
[AI] LRTA*搜索算法及其扩展算法
LRTA*搜索算法及其扩展算法
- 一、LRTA*搜索算法及其扩展算法的介绍
- 1、LRTA*
- 2、Prioritized-LRTA*
- 3、Weight-LRTA*
- 4、Upper-bounded-LRTA*
- 5、LRTA*(K)
- 6、LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K)
- 1、选择局部空间
- 2、更新局部空间
- 二、算法属性
- 1、最优解
- 2、收敛速度
- 3、资源约束
- 4、收敛稳定性
- 6、完备性 Completeness
- 8、效率 Efficiency
- 三、LRTA∗vsLRTA∗(K)vsLRTALS∗(K)LRTA^{*} \space vs \space LRTA^{*}(K) \space vs \space LRTA^{*}_{LS}(K)LRTA∗ vs LRTA∗(K) vs LRTALS∗(K)
- 1. Example of LRTA*
- 2. Example of LRTA*(k)
- 3. Example of LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K)
- 四、结论
- References
文档下载Download,其余参考文献也在该项目下
LRTA算法是一种实时启发式搜索算法,具有广泛的应用前景,但它仍有可以改进的地方,因此提出了许多扩展算法。本报告将在第一部分介绍LRTA及其扩展算法,在第二部分总结和比较各扩展算法的特性,并在第三部分将LRTA*(k)和LRTA∗ls(k)LRTA*_{ls}(k)LRTA∗ls(k)与LRTA*在实际应用中进行比较,最后是结论部分
一、LRTA*搜索算法及其扩展算法的介绍
1、LRTA*
LRTA是基于RTA的改进版,RTA会记录第二最优解,进而引导agent走向错误方向,LRTA通过记录最优解而不是第二最优解解决了这个问题。LRTA算法的核心是对节点的启发式值的更新,启发式值的更新使用启发式函数:H(s)=g(s,s′)+H(s′),H(s)=g(s, s')+H(s'),H(s)=g(s,s′)+H(s′),
其中H(s)表示前一节点的启发式值,g(s, s’)表示从节点s到s‘的代价,H(s’)表示当前节点的启发式值。LRTA的完整算法如下:

2、Prioritized-LRTA*
这一节单独开过一个章节
优先级扫描(Prioritized Sweeping)是一种用于强化学习问题的算法,它根据优先级排序的状态更新执行异步动态规划(Moore & Atkeson 1993) 1。如果一个状态的值函数有很大的潜在变化,则它具有很高的优先级。为了保持算法的实时保证,每个计划阶段都可以进行最多的β更新,并且只有潜在更新大于的状态才会被添加到队列中。优先级扫描被证明比q-学习和Dyna-PI更有经验效率(Moore & Atkeson 1993)。
上边是原文翻译过来的,主要就是说这个算法是按优先级给节点进行更新的,这个节点的值潜在变化越大优先级就越高,“潜在变化: Δ\DeltaΔ” 在下文程序二中给出了具体的计算方式。
下边才到了算法重点哈,下文的结构是先笼统讲一下P-LRTA*算法的流程,流程中用到的具体的三个函数伪代码将在流程下边进行详细介绍:
P-LRTA*(Prioritized简称P-)分为两个阶段,一个是规划阶段(planning phase),一个是动作阶段(action phase),我把具体操作步骤加粗了,未加粗的是各种算法特性之类的。
-
规划阶段
- P-LRTA*仅通过考虑邻近节点来更新当前节点(函数2:StateUpdate(s)),然后把已更新状态的节点的近邻节点加入队列,优先级是根据 Δ\DeltaΔ 的大小。
- 如果队列满了,就把队列中优先级低的移走(函数3:AddToQueue(s, Δ\DeltaΔ))。
- P-LRTA* 和 LRTA* 一样不需要对地图的初始信息,并且对不可见区域采用自由空间假设。
- 当队列大小为0时,P-LRTA等同于LRTA。
- 队列有明确的大小,这也严格保证了有限内存的使用。
- 当更新完当前节点的 h 值后,开始优先级更新
- 从队列顶部取最多 PS_MAX_UPDATE 个节点并使用函数1:Prioritized-LRTA(s) 进行更新
- 那些队列中没取完的节点下个规划阶段再用,这也产生了一个不连续的搜索空间,但这是有益的,因为
-
动作阶段
- Agent 从 s 节点移动到拥有最小 f(s,s′)f(s, s')f(s,s′) 的 s’ 节点, 其中 f(s,s′)=c(s,s′)+h(s′)f(s, s')=c(s, s')+h(s')f(s,s′)=c(s,s′)+h(s′),c(s,s′)c(s, s')c(s,s′)是节点s和s‘ 直接的距离,h(s’)是节点s’的启发式值。
下面介绍下用到的三个函数:
- 函数 1

函数1应该是主体函数了,输入就是 节点s,先判断s是不是目标节点,如果不是,就进入循环,先调用函数2更新当前节点的 h 值,然后它有个最大更新数,前面提到了,主要没超过这个更新次数并且队列里还有节点,就依次取出队列顶部的节点,只要不是目标节点,就更新h值,最后向 f 值最小的节点移动。 加粗部分对应上边加粗的步骤
-
函数 2

函数2用于更新节点h值,先判断s是不是目标节点,然后计算最低 f(s, s’),然后计算Δ\DeltaΔ,Δ\DeltaΔ就是用来衡量优先级的,Δ\DeltaΔ越大优先级越高。如果Δ\DeltaΔ大于0,就把节点s的所有临近节点加入队列,然后更新当前节点 s的启发式值 h -
函数 3

函数3 用于把节点加入队列,队列要是没满并且节点s不在里面,就加进入,否则,把优先级低的移走,再把s加入
3、Weight-LRTA*
文章指出LRTA存在两个问题,第一个问题是LRTA算法追求最优解,但这需要大量计算资源,违反了资源有界性,正如Simon [33]和Korf [22]所主张的,在现实问题中接近最优的解通常是可以接受的。即使LRTA算法找到了一个接近最优解的解,它仍然会继续探索未访问的状态以寻找最优解。
第二个问题是学习过程的不稳定,因为算法具有贪婪的特性,会急切地探索未访问的状态空间。随着算法的运行,LRTA算法会增加对已访问状态的启发式值,但并没有改变未访问状态的启发式值,由于算法会倾向于向启发式值更小的状态移动,因此它通常会倾向于探索未被访问的状态,这样做的结果就是它会经常穿过比已发现路径代价更高昂的路径。
为解决第一个问题,weight-LRTA*放弃了收敛到最优解以减少探索量。
对于一个常数 ε≥0\varepsilon \geq 0ε≥0,启发式函数 h(⋅)h(·)h(⋅) 满足 h(x)≤(1+ε)h∗(x)h(x) \leq (1+\varepsilon)h^{*}(x)h(x)≤(1+ε)h∗(x)
则 h(x) 叫做在 x 中 ε−admissible\varepsilon-admissibleε−admissible,满足上式的状态 x 叫做关于h(·) 的 ε−admissible\varepsilon-admissibleε−admissible状态, 在状态空间中为每个状态分配 ε−admissible\varepsilon-admissibleε−admissible 值的启发式函数叫做 ε−admissible\varepsilon-admissibleε−admissible启发式函数,ε\varepsilonε 叫做 h(·) 的权重。
对于 ε≥0\varepsilon \geq 0ε≥0,Weight-LRTA是LRTA算法的修改版本,其中初始启发式函数被松弛到仅ε−admissible\varepsilon-admissibleε−admissible。除了修改初始启发式函数外,其他部分与上文的LRTA算法相同(包括约束部分)。0-admissibility等于普通admissibility,因此LRTA是weight-LRTA*的一个特殊情况。
4、Upper-bounded-LRTA*
第三节提到LRTA*存在的两个缺点:1.LRTA*追求最优解,这需要大量计算资源。 2.LRTA*的学习过程不稳定,是因为算法贪婪的特性。
Upper-bounded-LRTA*在在包含不可逆作用的状态空间中不能给出上界。该文章提出 Upper-bounded-LRTA* 算法解决了上述和学习不稳定的缺点。
Upper-bounded-LRTA*使用另一个启发式函数 u(⋅)u(·)u(⋅) 和LRTA*的启发式函数 h(⋅)h(·)h(⋅).
对于一些问题,如滑块拼图和魔方,解的代价的上限是可以分析或者凭经验得出的,使用这些上限作为u(⋅)u(·)u(⋅)的 u0(⋅)u_{0}(·)u0(⋅)是可能的,只要它们满足简要描述的一些限制条件。当对上限没有可用的先验知识时,我们可以使用下列“无信息”的初始启发函数:
u0(x)={0,if x is a goal state∞,otherwiseu_{0}(x)=\left\{ \begin{aligned} 0, & \text{if x is a goal state} \\ \infty, & \text{otherwise} \end{aligned} \right. u0(x)={0,∞,if x is a goal stateotherwise
然后用下列公式来更新启发式评估,x是state,y是邻居state之一:
u(x)⟵min[u(x),k(x,y)+u(y)]u(x) \longleftarrow min[u(x), k(x, y)+u(y)]u(x)⟵min[u(x),k(x,y)+u(y)]
上式其实就是LRTA*的启发式函数。
Upper-bounded-LRTA*算法如下:


5、LRTA*(K)
该文作者把LRTA算法归为 无界传播(unbounded propagation, 中文用谷歌翻译的。。。囧),LRTA(K)归为有界传播(bounded propagation)
所谓无界传播:先让agent移动到新的位置,然后更新上一个位置的 h(n), 这样并不会立即更新该新位置的 h(n),而是指望未来再次移动后才会更新该位置的值。被更改 h 后的位置的影响会进一步传播给其后继,依此类推。 该过程不断迭代,直到没有执行进一步的更改。
有界传播:限制一步最多只能更新有限K个位置的h ,这样用于传播的计算量就是有界的。在此说明:这k个位置只能是从初始位置到当前位置的路径之间的位置
LRTA* 算法的缺点如下:
-
在有限的时间内移动。无界传播中涉及的状态数在连续步骤中可能不同,因此所需的计算量可能会在步骤之间发生变化(说实话,这里我没看懂)。 这违背了实时搜索必须在限定时间内执行单个移动的要求。
-
作用于附近。 无界传播可以远离当前状态。 这违反了实时搜索的基本假设,即前瞻和更新操作只能在当前状态附近完成。(我没明白,无界传播不也是在当前状态附近来回震荡直到跳出局部最小值吗?)
LRTA*(K)优势如下:
-
初解:如果第一个解不涉及循环,LRTA*(K)将表现为LRTA*,然而,这种情况很少发生。实验上,LRTA*(K)在较短的计算时间内发现了比LRTA更短的解。
-
收敛:LRTA*(K)记录的h值更接近精确值,这导致LRTA*(K)在测试基准中比LRTA*(步骤数、试验次数和总CPU时间)更快地收敛。其他算法(FALCONS)也会出现这种情况。
-
解的稳定性:获得更高质量的解使解决方案和增加的稳定性之间的差异更小。
写在最后,其实我也理解的不是很深,具体算法如下:

6、LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K)
LRTA*(K)算法每次要更新队列Q里的state,但有三点缺陷:
-
如果state y进入 Q,但重考虑后 h(y) 不会改变,这是一种浪费时间的努力
-
可能有的state进入Q不止一次,要经过多次更新才能打到最终值
-
进入Q的state的顺序以及K的取值都会影响最终结果
算法概览:LRTA∗LS(k)LRTA*_{LS}(k)LRTA∗LS(k) 算法把states分为内部states(用集合 I∈XI \in XI∈X 表示, X是所有state的集合)和边缘states (用集合 F∈XF \in XF∈X 表示),I∩F=∅I \cap F=\emptysetI∩F=∅,LRTA∗LS(k)LRTA*_{LS}(k)LRTA∗LS(k) 选择当前状态的局部空间并更新其内部state, 内部states只更新一次值,内部states的数量上限为K(集合 I 的长度最高为K),该算法继承 LRTA* 和 LRTA*(K) 的良好属性。
1、选择局部空间
步骤如下:
-
设 I=∅I = \emptysetI=∅, Q = {x| x是当前state}
-
循环直到 Q 空了或者 ∣I∣==K|I| == K∣I∣==K:
从Q中提取state w, 如果 w 就是目标,就跳出循环。否则,检查是否存在 h(w)
其中h(w)h(w)h(w)是state w的启发值,{Succ(w)−I}\{Succ(w)-I\}{Succ(w)−I}表示w的所有后继state Succ(w)Succ(w)Succ(w) 减去 I 集合中的交集,剩下的不在 I 中的后继state,g(w, v)表示从state w 到 v 的路程代价。
如果满足上式(文中称之为“更新条件”),就把 w 加入 I,v 加入 Q -
把 I 中所有state的不在I中的后继state加入边缘集合 F
2、更新局部空间
步骤如下:
当 内部集合 I 非空时置行下列循环:
-
计算连接state对 (i,f),i∈I,f∈F,f∈Succ(i)(i, f), i \in I, f \in F, f \in Succ(i)(i,f),i∈I,f∈F,f∈Succ(i)
-
更新 h(i)=g(i,f)+h(f)h(i) = g(i, f) + h(f)h(i)=g(i,f)+h(f)
-
把 iii从 III 中移除,把 iii 加入 FFF
二、算法属性
1、最优解
能否找到最优解是衡量搜索算法性能的一个重要属性,最优解当然是我们可以期待的最佳结果,但在实时搜索领域,需要搜索算法在有限的时间内给出解决方案,所以很多时候次优解也是可以接受的。
-
LRTA*: 是的,有最优解,如果它存在
-
Prioritized LRTA*: 当存在一个达到目标的最优解,并且初始启发式是可接受的,就有最优解
-
Weight LRTA*: 次优解
-
Upper-bounded LRTA*: 有最优解,如果 δ≥2\delta\geq2δ≥2.
-
LRTA*(K): 与LRTA一样有最优解,且比LRTA花更少的时间找到更短的路径解
-
LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K): 是的,有最优解,如果它存在
2、收敛速度
算法的收敛速度是指在允许的时间内得到一个相对准确的数值,或得到一个满意的结果所需的迭代次数,所以收敛速度也是衡量算法性能的属性之一。
-
LRTA*: 在有限空间内收敛到每个最优解的精确值
-
Prioritized LRTA*: 比LRTA*更快,因为加速了学习过程。
-
Weight LRTA*: 比LRTA*更快,因为没有要求解决方案必须是最优的。
-
Upper-bounded LRTA*: 加速收敛并不是主要目标,有时甚至比LRTA*收敛得更慢,以使收敛过程更加稳定。
-
LRTA*(K): 比LRTA快,但每一步都比LRTA有额外的计算量.
-
LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K): 比LRTA*(K)更快.
3、资源约束
资源约束属性是用来衡量算法所占资源的大小。有些算法不考虑占用的资源量,所以当算法的资源耗尽时,将很难运行,所以资源约束也是衡量算法性能的一个重要指标
-
LRTA*: 没有资源约束
-
Prioritized LRTA*: 保证对使用的内存有一个硬性限制
-
Weight LRTA*: 比LRTA*节省内存。
-
Upper-bounded LRTA*: 比LRTA*节省成本。
-
LRTA*(K): 比LRTA*节省成本。
-
LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K): 成本低于LRTA*(K),但占用的内存比LRTA*多。
4、收敛稳定性
收敛稳定性用于衡量算法在收敛过程中对错误(舍入错误、截断错误等)的不敏感性,也就是说,一个稳定的算法可以得到原问题的相邻问题的精确解。
-
LRTA*: LRTA*并不能保证解决方案质量的稳定提高
-
Prioritized LRTA*: 没提
-
Weight LRTA*: 比LRTA*更稳定.
-
Upper-bounded LRTA*: 当 δ=2\delta=2δ=2时, Upper-bounded LRTA* 比 Weight LRTA*更稳定.
-
LRTA*(K): 比LRTA*更稳定.
-
LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K): 没提
6、完备性 Completeness
完备性是指当问题至少有一个解决方案时,搜索算法保证能在有限时间内找到一个解决方案。
报告中列出的LRTA*及其扩展算法都能在有限空间内找到一个最优解。
8、效率 Efficiency
算法效率与计算资源(包括时间和空间资源)有关,使用的计算资源越少,效率越高,这也是衡量算法性能的一个属性。
- LRTA*:取决于问题空间的结构、初始和目标状态的分布以及初始启发式值。
- Priori LRTA*:比LRTA*更具经验效率。
- Weight LRTA*: 比LRTA*更效率。
- Upper-bounded LRTA*:必须将扩展状态减少到LRTA*的一半以下以提高内存效率。
- LRTA*(K):比LRTA*更有效,花更少的时间可以找到更短的路径解决方案。
- LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K):比LRTA*(K)更有效率,因为解决了它的几个低效率问题。
三、LRTA∗vsLRTA∗(K)vsLRTALS∗(K)LRTA^{*} \space vs \space LRTA^{*}(K) \space vs \space LRTA^{*}_{LS}(K)LRTA∗ vs LRTA∗(K) vs LRTALS∗(K)
本节将使用一个如下图1所示的例子来比较LRTA*、LRTA*(k)和LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K)算法的性能。如图1.(a)所示,有四个位置A、B、C和D。从位置D开始,A是目标位置,每次只能移动一步,每个位置之间的成本g(i, j) = 1。图1.(b) 中的数字表示该位置的启发式数值。而绿色部分表示当前的位置

下边的内容有些懒得翻译了,但都很好理解嘿嘿
1. Example of LRTA*
使用LRTA*算法的例子如图2所示,每个步骤的细节见下文。
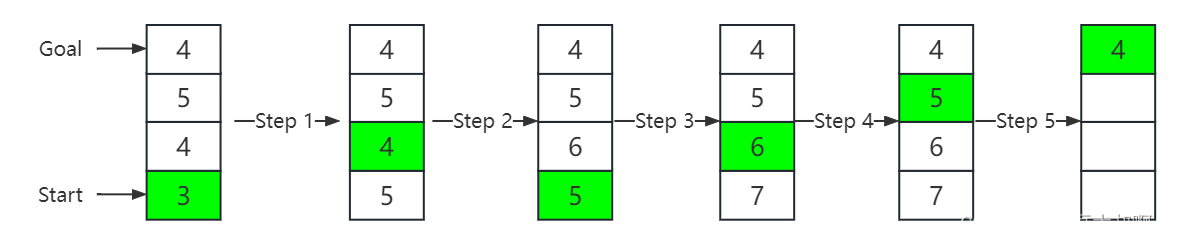
- Initialization: Start from D, which heuristic value is 3, and the goal position is A.
- Step 1: The agent moves to C from D, and updates h(D)=h(C)+g(C,D)=4+1=5h(D)=h(C)+g(C, D)=4+1=5h(D)=h(C)+g(C,D)=4+1=5.
- Step 2: The agent moves to D from C, and updates h(C)=h(D)+g(C,D)=5+1=6h(C)=h(D)+g(C, D)=5+1=6h(C)=h(D)+g(C,D)=5+1=6.
- Step 3: The agent moves to C from D, and updates h(D)=h(c)+g(C,D)=6+1=7h(D)=h(c)+g(C, D)=6+1=7h(D)=h(c)+g(C,D)=6+1=7.
- Step 4: The agent moves to B from C, and updates h(C)=h(B)+g(B,C)=5+1=6h(C)=h(B)+g(B, C)=5+1=6h(C)=h(B)+g(B,C)=5+1=6.
- Step 5: The agent moves to A from B, and reaches the goal.
==注意:==第一次在C位置的时候,上下都是5时(原论文及伪代码都没提两边相同时走哪边),agent当然有概率往上走从而避免无用的步骤,但也有概率进行无用的步骤,后边两个扩展算法完全避免了这种无用步骤的可能,所以在这个例子中是可以看出那俩是比LRTA*性能更优越。
2. Example of LRTA*(k)
使用LRTA*(k)算法的例子如图3所示,每个步骤的细节见下文。
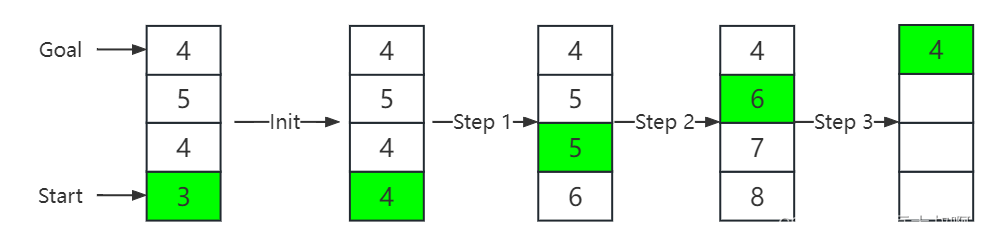
-
Initialization: Set the length of Q as k=4k=4k=4. The agent starts from D, first update h(D)=4. Q={D}.
-
Step 1: The agent moves from D to C. Update h(C)=h(D)+g(C,D)=4+1=5h(C)=h(D)+g(C, D)=4+1=5h(C)=h(D)+g(C,D)=4+1=5. h© changes, then update C’s successor h(D)=h(C)+h(C,D)=5+1=6h(D)=h(C)+h(C, D)=5+1=6h(D)=h(C)+h(C,D)=5+1=6. Since B is not on the path from the initial position to the current position, B is not considered. h(D) changes, then update D’s successor h©, but h© has already been updated in this step, so the algorithm stops here. At this step Q={C, D, C}.
-
Step 2: In this step, h(B)
-
Step 3: In this step, h(A)
3. Example of LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K)
The example of using the LRTA∗LS(K)LRTA*_{LS}(K)LRTA∗LS(K) algorithm is shown in Figure 4, and the details of each step are shown below.
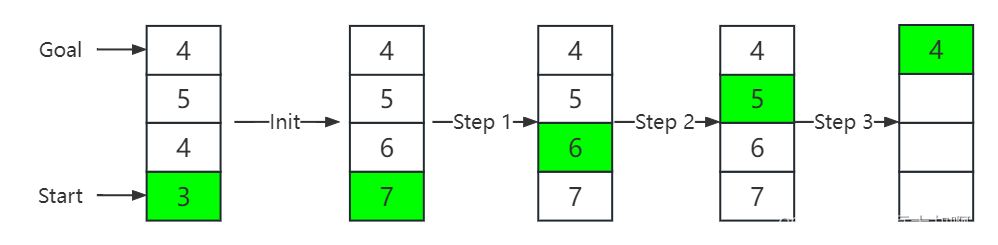
-
Initialization: Set the length of I as k=4k=4k=4. The agent starts from D, so the current position is D, add D to Q={D}, $I = \emptyset $.
- Selecting the local space
- First, take D from Q, then according to the formula h(w)
- Then adds C to Q, and add D to I. Now Q = {C}, I = {D}.
- Q is not empty, take C from Q, the minv∈Succ(C)−Ih(v)min_{v \in {Succ(C)-I}}h(v)minv∈Succ(C)−Ih(v) is h(B). h(C)
- Then adds B to Q, and add C to I. Now Q = {B}, I = {C, D}.
- Q is not empty, take B from Q, the minv∈Succ(B)−Ih(v)min_{v\in {Succ(B)-I}}h(v)minv∈Succ(B)−Ih(v) is h(A). h(A)
- Now Q is empty, add B to F, and the loop ends. Now Q=∅,I={C,D},F={B}Q=\emptyset, I=\{C, D\}, F=\{B\}Q=∅,I={C,D},F={B}.
- First, take D from Q, then according to the formula h(w)
- Updating the Local Space
- I={C, D}, F={B}, only one pair of connected states (B, C).
- Update h( C)=h(B)+1=5+1=6.
- Move C from I, add C to F.
- Now I={D}, F={B, c}. Only one pair of connected states (C, D).
- Update h(D)=h( C)+1=6+1=7.
- Move D from I, add D to F.
- Now I=∅I=\emptysetI=∅, F={B, C, D}. I is empty, so the loop ends.
- Selecting the local space
-
Step 1: After initialization, the heuristic value of A, B, C, and D is 4, 5, 6, 7. The agent moves from D to C. The current position is C, so Q={C}, I=∅I=\emptysetI=∅
- Selecting the local space
- Take C from Q, then the minv∈Succ(C)−Ih(v)min_{v \in {Succ(C)-I}}h(v)minv∈Succ(C)−Ih(v) is h(B). h(C)
- Now Q is empty, add B to F, and the loop ends. Now Q=∅,I=∅,F={B}Q=\emptyset, I=\emptyset, F=\{B\}Q=∅,I=∅,F={B}.
- Take C from Q, then the minv∈Succ(C)−Ih(v)min_{v \in {Succ(C)-I}}h(v)minv∈Succ(C)−Ih(v) is h(B). h(C)
- Updating the Local Space
- I=∅I=\emptysetI=∅, the loop ends.
- Selecting the local space
-
Step 2: The agent moves to B, the current position is B, so Q={B}, I=∅I=\emptysetI=∅.
- Selecting the local space
- Take B from Q, then the minv∈Succ(C)−Ih(v)min_{v \in {Succ(C)-I}}h(v)minv∈Succ(C)−Ih(v) is h(A). h(B)
- Now Q is empty, add A to F, and the loop ends. Now Q=∅,I=∅,F={A}Q=\emptyset, I=\emptyset, F=\{A\}Q=∅,I=∅,F={A}.
- Take B from Q, then the minv∈Succ(C)−Ih(v)min_{v \in {Succ(C)-I}}h(v)minv∈Succ(C)−Ih(v) is h(A). h(B)
- Updating the Local Space
- I=∅I=\emptysetI=∅, the loop ends.
- Selecting the local space
-
Step 3: After step 2, the agent moves to A, reaches the goal, and the algorithm ends.
四、结论
在本报告中,列举了LRTA的五个扩展,即prioritized-LRTA, weight LRTA*, upper-bounded LRTA*, LRTA*(k), and LRTA∗LS(k)LRTA*_{LS}(k)LRTA∗LS(k), 并进行了简要介绍。prioritized-LRTA根据状态的优先级来更新启发式数值,与LRTA相比,它提高了算法的效率。weight LRTA和upper-bounded LRTA主要解决了LRTA*在搜索和求解收敛过程中解的质量不稳定的问题。LRTA(k)和LRTA∗LS(k)LRTA*_{LS}(k)LRTA∗LS(k)减少了资源约束所使用的资源,提高了搜索效率。
第二部分的列表总结了每种算法的一些特性进行比较,包括最优解、拟合速度、资源约束、拟合稳定性、完备性和效率。比较结果表明,每种扩展算法在某些属性上比LRTA*更先进。
第三部分通过一个实际例子比较了LRTA*、LRTA*(k)和LRTA∗LS(k)LRTA*_{LS}(k)LRTA∗LS(k)在实际应用中的表现,可以看出LRTA∗LS(k)LRTA*_{LS}(k)LRTA∗LS(k)比前两者需要的步骤都少,这也证明了该算法确实改进了LRTA*。
References
[1] Richard E Korf. Real-time heuristic search. Artificial intelligence, 42(2-3):189–211, 1990.
[2] Masashi Shimbo and Toru Ishida. Controlling the learning process of real-time heuristic search. Artificial Intelligence, 146(1):1–41, 2003.
[3] Andrew W Moore and Christopher G Atkeson. Prioritized sweeping: Reinforcement learning with less data and less time. Machine learning, 13(1):103–130, 1993.
[4] D Chris Rayner, Katherine Davison, Vadim Bulitko, and Jieshan Lu. Prioritized-lrta*: Speeding up learning via prioritized updates. In Proceedings of the National Conference on Artificial Intelligence (AAAI), Workshop on Learning For Search, 2006.
[5] Carlos Hern ́andez and Pedro Meseguer. Lrta*(k). In Proceedings of the 19th international joint conference on Artificial intelligence, pages 1238–1243, 2005.