
强化学习(1)
MDP:描述为离散时间随机控制过程。具体来说,将离散时间随机过程定义为下标变量是一组离散或特殊的值(相对于连续值来说)的随机过程。
A2C(Advantage Actor-Critic):优势Actor-Critic模型,更新所有子模型的参数。
A3C(Asynchronous Advantage Actor-Critic):异步优势Actor-Critic模型,具有多个相互配合工作的子模型,并且这些子模型独立更新参数。
与基于值的方法相比,基于策略的方法倾向于收敛到更好的解决方案,尤其擅长学习随机过程,在高维空间中更显著有效,计算成本明显降低。
梯度法指向微分函数的最陡方向。
策略被定义为在给定环境状态下所有动作的概率分布,数学描述如下:
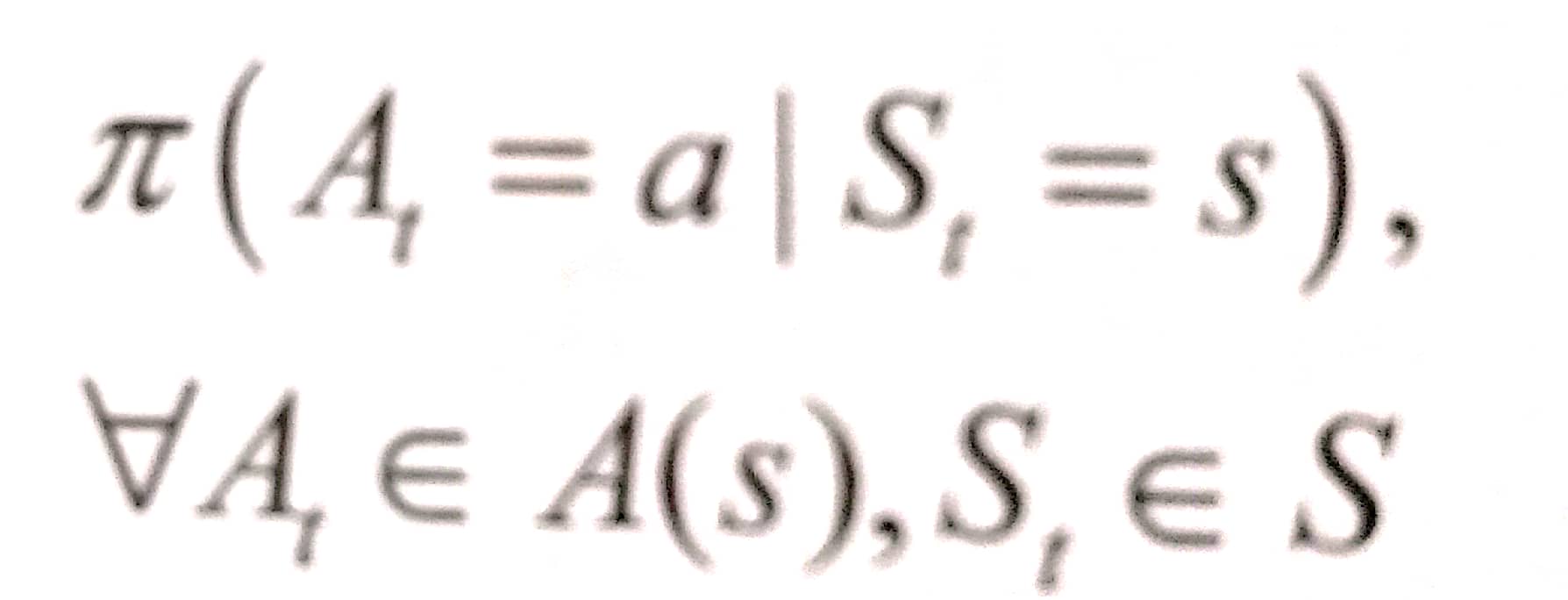
回合(episode):agent从一个特定状态出发,直到任务结束(达成问题目标或彻底失败),被称为一个完整的回合。
函数的梯度表示函数具有最大增长率的点,其大小是函数图形在该方向上的斜率。通常将梯度乘以一个学习率,该学习率确定了收敛到函数最优解的速度。梯度通常定义为给定函数的一阶导数。
基于梯度下降的优化方法:常用于线性回归以及用于多层感知器权重优化的反向传播。
策略梯度存在抽样效率的问题,策略梯度不会区分一个回合中采取的各个动作,意味着,如果在一个回合中采取的动作带来了很高的奖励,即使这些动作中的某些子集不是很理想,我们也可以得出结论,这些动作都是不错的。另外,策略梯度趋向于收敛到局部最大值而不是全局最大值。
策略梯度方法的目的是利用基于梯度最优化来选择一组动作,使得在给定目标情况下,这些动作在环境中实现最优结果。
折扣奖励:通过折扣奖励,使得原本为无穷的总和变得有限。如果不采取折扣奖励,这些奖励的总和将无限增长,将无法收敛于最优解决方案。
PPO通过对目标函数施加惩罚,然后在新改进的梯度下降上应用梯度策略,来专门处理策略梯度,从而避免限于局部最大值。
对于梯度下降法来说,当梯度较小时,比起具有较大梯度值的神经网络,权重优化将容易得多。
深度Q学习很大程度上源于Q学习,这两种方法之间的唯一真正区别是,深度Q学习近似处理其Q表中的值,而不是尝试手动填充它们。
经验回放是通过保存观察到的经验以便利用它们,从而有助于减少可能观察到的经验之间的关联性。
区别连续控制系统和离散控制系统的方式是,前者中的变量和参数是连续的,后者中的是离散的。强化学习应用背景中的连续过程示例包括驾驶汽车或教机器人走路。离散控制过程示例包括车杆游戏,钟摆问题等。
深度Q学习由于高估的存在,经常学到非常高的动作值,高估会导致策略不佳,并容易引起模型偏差。可能会陷入局部最优。