
C语言 结构体进阶 结构体、枚举、联合详解(1)
目录:
结构体
结构体类型的声明
结构的自引用
结构体变量的定义和初始化
结构体内存对齐
结构体传参
结构体类型的声明
struct tag
{member-list;//成员列表
}variable-list;//变量列表假设我们要定义一个学生结构体(描述一个学生):
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[10];//学号
};注意!这里大括号外面的分号不能丢。
如何使用我们的结构体呢?下面就演示一下结构体的使用:
struct Stu
{char name[20];int age;float weight;
}s4 ,s5,s6;//除了在主函数内部创建变量,也可以在结构体后创建变量列表,这里的变量是全局变量
int main()
{struct Stu s1;struct Stu s2; //这里我们创建了3个学生变量struct Stu s3; //局部变量return 0;
}除了此类型的结构体之外,我们还有匿名的结构体类型。例如:
struct
{int a;char b;float c;
}x;
struct
{int a;char b;float c;
}a[20], * p;注意:匿名结构体类型只能停留在这种状态,它属于一个全局变量,我们不能在主函数当中写出这种代码:*p=&x,这是不对的。
结构的自引用
首先这是一个错误的示例,在自己的结构体当中不能引用和自己相同的变量
struct node
{int data;struct node next;//错误
};修改:我们可以在自己的结构体当中包含一个自己类型的指针。
struct node
{int data;struct node *next;
};
int main()
{struct node n1;struct node n2;n1.next = &n2;//意思是n1包含的指针指向n2,这样就把n1和n2链接起来了return 0;
}使用typedef 对结构体进行重命名
typedef struct Node
{int data;struct Node* next;
}Node;//结构体类型名叫Node结构体变量的定义和初始化
定义:简单举例
struct Point
{int x;int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//p1和p2全是全局变量初始化:
struct S
{int a;char c;
}s1;//全局变量
struct S s3;//全局变量
struct B
{float f;struct S s;
};
int main()
{struct S s2 = { 100,'q' };struct S s3 = { .c = 'r',.a = 10 };struct B sb = { 3.14f,{200,'h'} };//结构体中有结构体,初始化要加大括号printf("%f,%d,%c\n", sb.f, sb.s.a, sb.s.c);return 0;
}结构体内存对齐
结构体在内存当中存放都会有一个对应的规则,这个规则也就是结构体内存对齐。也就是说结构体类型在内存当中存放并不是说一个变量占多少个字节,相加就是这个结构体类型占用的空间,并不是的。
结构体内存对齐规则:
1. 第一个成员在与结构体变量偏移量为0的地址处。
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
(VS中默认的值为8,gcc环境没有对齐数,是成员默认大小)
3. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整
体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
单摆规则我们肯定不会明白,直接上例子:
例1:

例2:嵌套结构体的内存
struct S1
{char c1;int i;char c2;
};
struct S2
{int a;struct S1 s;
};
为什么存在内存对齐?
1. 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特 定类型的数据,否则抛出硬件异常。 2. 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访 问。 结构体内存对齐总体来说是拿空间换时间的做法,为什么呢?
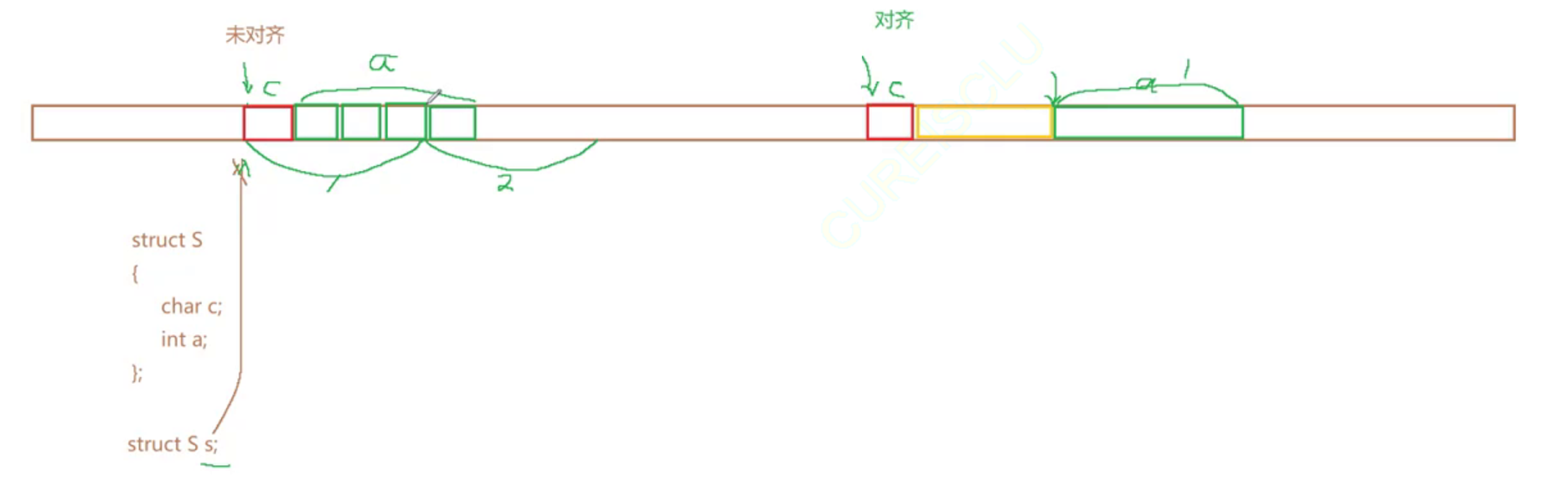
对于一个32位的机器来讲,未对齐时,我们需要两次读取才能知道在一个空间当中我们存储的是a和c,但是对齐时,我们只需要一次读取就能知道我们存储的是a和c,所以说这是一种拿空间换取时间的做法。
在我们结构体类型的存储中,我们也不是盲目的去浪费空间,所以这里我们在写结构体时,尽量的把占用内存较小的类型集中在一起。
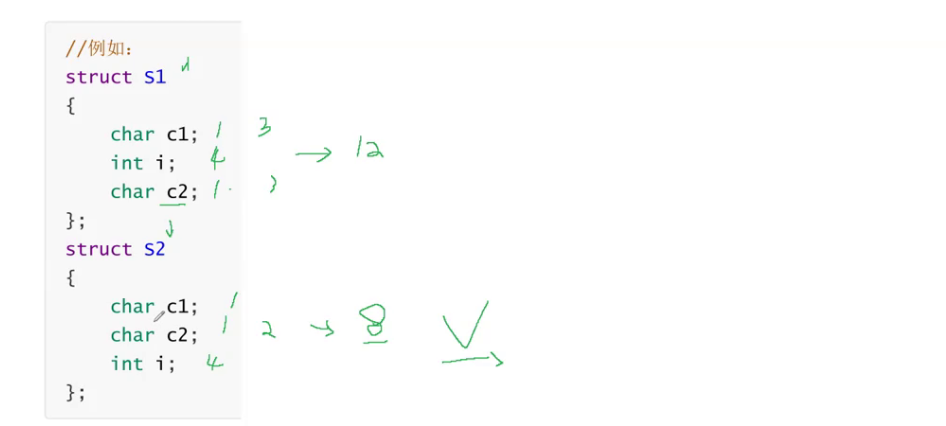
使用offsetof宏计算偏移量:
#include
struct S
{char c;int a;
};
int main()
{struct S s = { 0 };printf("%d\n", offsetof(struct S, c));printf("%d\n", offsetof(struct S, a));return 0;
} 
修改默认对齐数:
#pragma 这个预处理指令,这里我们再次使用,可以改变默认对齐数。
#pragma pack(8)//设置默认对齐数为8
struct S1
{char c1;int i;char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
#pragma pack(1)//设置默认对齐数为1
struct S2
{char c1;int i;char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
int main()
{//输出的结果是什么?printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}设置默认对齐数只能设置为类似2^n。
结构体传参
struct S
{int data[1000];int num;
};
struct S s = { {1,2,3,4}, 1000 };
//结构体传参
void print1(struct S s)
{printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{printf("%d\n", ps->num);
}
int main()
{print1(s); //传结构体print2(&s); //传地址return 0;
}
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。 如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的 下降。 所以结构体传参的时候,最好传递结构体的地址。
在函数接受地址时,最好在地址前使用const来修饰,确保指针安全,不会改变。