
【大数据常用组件】Flume组件总结
目录
- 简介
- 基础架构
- 常见的Source组件类型
- 常见Sink 组件类型
- Flume拦截器(Interceptor)
- Flume配置文件案例
- Flume数据流模型
简介
Flume是一个基于分布式的海量日志采集、聚集、传输系统,在大数据领域中得到广泛使用,主要用于采集源数据,工作于数仓中的ODS层。
基础架构
Flume在大数据架构中的角色地位
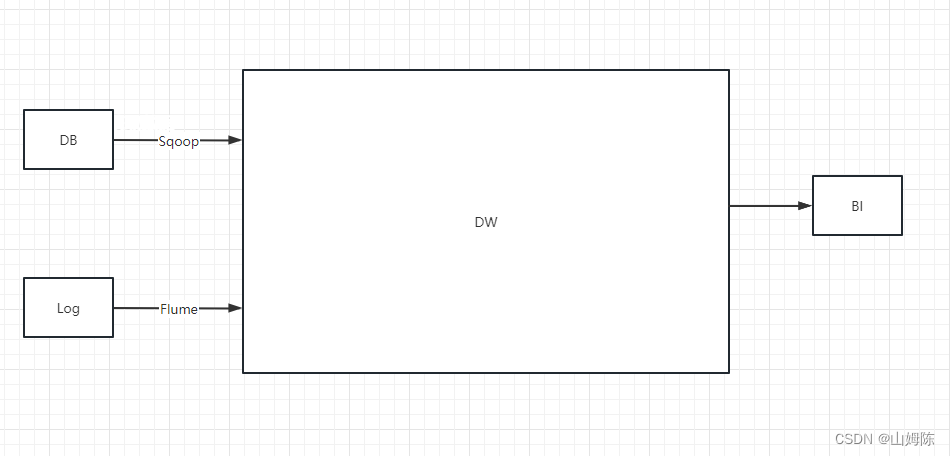
FIume组成结构

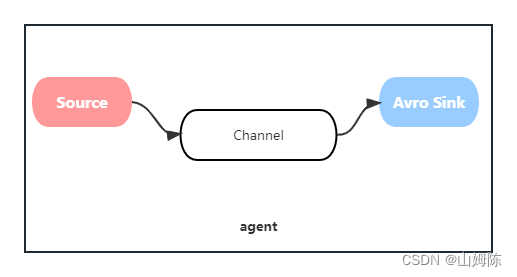
flume基础架构主要由五大组件构成:
- event: 数据传输的基本单位,由header和body两部分组成,flume每次从数据源头采集的数据都会以event为数据单位传递到下一个节点;
- agent: 数据采集传输的工作进程,由source、channel、sink 三大工作组件构成:
1. source :source是负责接收数据到flume agent的组件,针对不同的数据来源,flume提供了不同类型的source组件,包括netcat、exec、spoolDir、tailDir等;
2. channel :channel类似于队列的功能,用于缓存source采集到的数据,等待下一个组件节点来进行消费,flume提供了memory和file两种类型的channel
memory channel:工作于内存的队列,性能极高,但存在数据丢失的风险,若服务器宕机,缓存于队列中的数据将会丢失。
file channel: 所有的数据将会写入到磁盘中,能保证数据不会丢失;
3. sink :负责输出从channel中消费的数据,可以将本agent流转的event数据单元传递到下一个agent,也可以直接传输到数据存储介质如Hive、hbase等数仓组件。
常见的Source组件类型

1、Netcat Source
netcat source可以通过监听一个特定的端口,待端口有数据传入时,将数据采集到
2、Avro Source
avro source同netcat source一样通过监听特定的端口号来采集到端口传入的数据,和netcat不同的是,avro source采集的数据都会经过序列化,然后再进行反序列化输出,而netcat采集的数据都会转换成字符串。
3、Exec Source
exec source 可以采集到特定命令下输出到控制台的日志数据
4、TailDir Source
TailDir Source支持断点续传, 通过监听某个特定的文件,待文件有追加时,将追加的内容采集
5、SpoolDir Source
flume可以监控特定文件夹下的所有文件,将该文件夹下新增的文件当做是source来处理,如果已经读取过的文件有更新,SpoolDir Source将不会再次进行读取
6、Kafka Source
支持从kafka某个topic中采集数据,此时kafka source 将作为一个消费者从kafka中消费数据。
常见Sink 组件类型

1、HDFS Sink
hdfs sink支持将从channel中获取到的数据传输到Hadoop生态中的hdfs存储组件
2、Hive Sink
支持将数据发送到hive特定的表或者分区中,一旦hive接收到相应的event数据后,可以通过hql立刻被查询出来;此外还有Hbase Sink,作用和Hive Sink相似。
3、Avro Sink
当fluent的架构采用多agent联动时,可以通过avro类型的sink与source进行对接,如:当一个agent的数据需要传递到另一个agent时,此时负责对接两个agent的sink和source需要用到Avro类型的组件进行序列化和反序列化。
Flume拦截器(Interceptor)
flume agent可以对source采集到的event数据进行拦截,在数据还未传递到channel节点之前,都可以对数据进行转换或者删除;flume提供了多种类型的拦截器,常见的有timestamp和regex拦截器。
1、timestamp拦截器
支持对event的header部分插入时间戳
2、host拦截器
对event头部插入的关键字为主机的地址,这里的主机指的是agent所在的主机
3、regex 拦截器
通过匹配正则表达式,来过滤掉不需要的数据,达到数据清洗的目的。
Flume配置文件案例
# 定义agent各组件名称
a1.sources = r1
a1.sinks = s1
a1.channels = c1# 定义source组件(这里用的是netcat,所以需要配置监听的地址及端口号)
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# 定义source组件
a1.sinks.s1.type = # 定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 通过channel绑定组件之间的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Flume数据流模型
上一篇:Java枚举