
81、Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
简介
主页:https://dorverbin.github.io/refnerf/

NeRF在镜面反射上表现不好,有两个原因。一个是,用出射光反方向作为视角,不好插值;另一个是,NeRF会用各向同相的内部光源来假装镜面反射,结果是半透明或雾状的模糊。
Ref-NeRF用射光反方向作为输入,因为表面的取向不影响它,因此MLP能在上面更好地插值。
一个问题是,入射光反方向需要找法向量,而NeRF生成的几何不够好,上面的法向量噪声过多。
Ref-NeRF在volume density上加了一个新的正则化器,激励volume density集中在表面上,同时获得更好的法向量。
实现流程
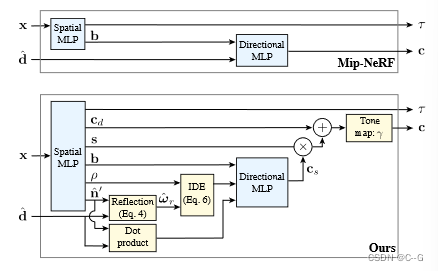
Structured View-Dependent Appearance
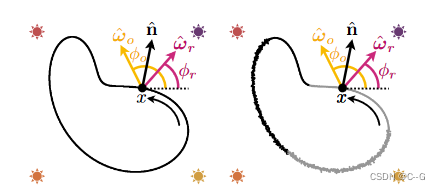
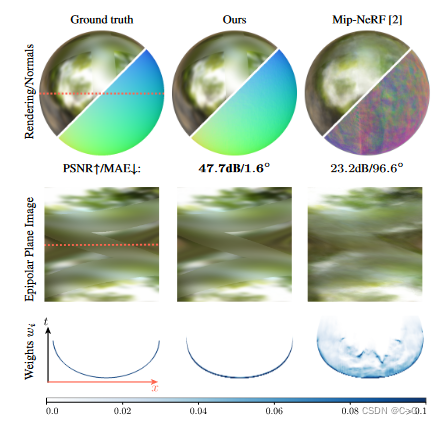
上图左边是光滑表面,右边是表面光滑程度、材质随空间位置变化而变化
ω^0\hat{\omega}_0ω^0 就是从相机原点出发的射线的方向的反方向,与法线的角度为 ϕ0\phi_0ϕ0
ω^r\hat{\omega}_rω^r 是实际的光线入射方向的反方向(outgoing radiance),与法线的角度为 ϕr\phi_rϕr
图像四个角为四个点光源
那么为什么 反射光 ω^r\hat{\omega}_rω^r,作为输入比用外向辐射 ω^0\hat{\omega}_0ω^0(-d)作为输入更好
首先,新视角合成本质上是一种插值
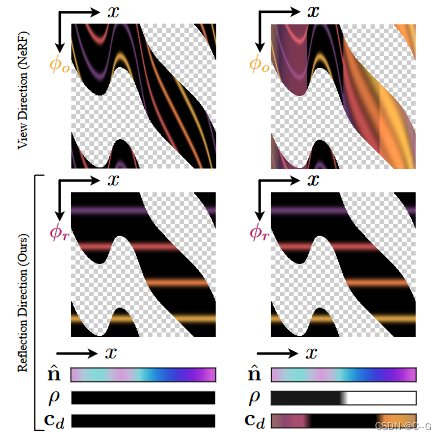
实际上是对图中黑色部分进行插值,而不是要补充满整幅图,对棋盘格插值。
在 x 移动的过程中,很明显会出现视线盲区,比如右上角的紫色平行光照过来,物体背部无论如何是无法通过新视角合成得到的,能看到的地方对应的是下图中紫色线条的部分,视线盲区对应的也就是棋盘格的地方。
所以这幅图就好理解了,黑色部分是可见部分,棋盘格是视线盲区,四种颜色的线条只是为了举例而已,实际上黑色部分就是光线从360度方向打过来后可以进行新视角合成的部分。
既然要对黑色部分进行插值,那么这个插值函数越简单越好,查看第一行的 ϕ0\phi_0ϕ0图像,这个线条非常扭曲,明显是个高次函数,拟合起来插值很困难,而第二行 ϕr\phi_rϕr 的图像,每条线都是常数,所以想对黑色部分插值轻而易举。
这就是为什么采用反射方向作为插值输入的最核心思想。
directional MLP作为插值核,模型能够更好地“共享”附近点之间的外观观察,从而在插值视图中呈现更真实的视相关效果。
输入是很远的太阳光,所以入射角认为是恒定的,所以 ϕr\phi_rϕr 不会变
Accurate Normal Vectors
先前基于nerf的模型通过使用空间MLP来预测任何3D位置的单位向量,或者使用体积密度相对于3D位置的梯度来定义场景中的法向量场,即如下公式:
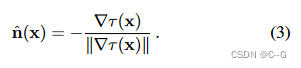
但是体密度场存在两个局限性:
- 从其体积密度梯度估计的法向量(如上式)通常具有极大的噪声
- NeRF倾向于“伪造”高光,通过在物体内部嵌入发射器,并用“雾天”漫反射表面部分遮挡它们
这是一个不太理想的解释,因为它要求表面的弥散内容是半透明的,以便嵌入的发射器可以“发光”
解决第一个问题,使用预测法向量来计算反射方向
对于沿着射线的每个位置 xix_ixi,从空间MLP输出一个3维向量,然后对其进行归一化以获得预测的法向量 n^i‘\hat{n}_i`n^i‘。
使用一个简单的惩罚将这些预测的法线与沿着每条射线 {n^i}\{\hat{n}_i\}{n^i}的底层密度梯度法线样本联系起来
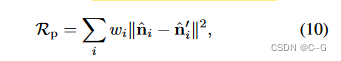
wiw_iwi 是第 i 个样本沿射线方向的权重(体渲染公式)
MLP预测的法向量往往比梯度密度法向量更平滑,因为梯度算子在MLP的有效插值核上充当高通滤波器
解决第二个问题,提出一个正则化项惩罚了“背向”的法线,即远离相机,沿着射线的样本,这样有助于射线的渲染颜色
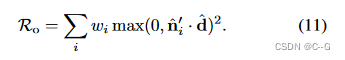
当样本是“可见的”(高wiw_iwi)并且体积密度沿射线下降时(即n^i‘\hat{n}_i`n^i‘和射线方向 d^\hat{d}d^ 之间的点积为正),样本会受到惩罚
这种法线方向惩罚阻止了模型将反射解释为隐藏在半透明表面下的发射器,并且由此产生的改进法线使Ref-NeRF能够计算精确的反射方向,用于查询 directional MLP。
Reflection Direction Parameterization
将 outgoing radiance 重新参数化为视图方向关于局部法向量的反射函数
ω^0=−d^\hat{\omega}_0 = -\hat{d}ω^0=−d^ 从空间中某一点指向相机的单位向量,n^\hat{n}n^ 为该点的法向量
对于关于反射视图方向旋转对称的BRDFs,有f(ω^i,ω^0)=p(ω^i,ω^0)f(\hat{\omega}_i,\hat{\omega}_0) = p(\hat{\omega}_i,\hat{\omega}_0)f(ω^i,ω^0)=p(ω^i,ω^0),依赖视图的辐射亮度仅是 ω^r\hat{\omega}_rω^r 的函数
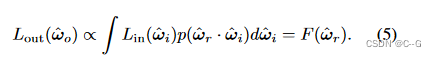
通过使用反射方向查询 directional MLP,可以有效地训练它将这个积分输出为 ω^r\hat{\omega}_rω^r 的函数
更一般的BRDFs可能会由于菲涅耳效应等现象而随视角方向和法向量之间的角度而变化,因此将 n^⋅ω^0\hat{n}\cdot\hat{\omega}_0n^⋅ω^0 输入到 directional MLP,以允许模型调整底层BRDF的形状
Integrated Directional Encoding
在具有空间变化材质的真实场景中,辐射度不能仅表示为反射方向的函数。
较粗糙的材料外观随反射方向变化缓慢,而较光滑或有光泽的材料外观变化迅速。
论文提出 Integrated Directional Encoding (IDE),通过IDE,directional MLP能够有效地表示具有任何连续值粗糙度的材料的传出辐射度函数
首先,对方向使用球面调和函数 {Ylm}\{Y^m_l\}{Ylm} 进行编码
然后,通过编码 ω^r\hat{\omega}_rω^r 的分布而不是单个向量,使 directional MLP能够推理具有不同粗糙度的材料
这里使用归一化球面高斯分布(vMF),以 ω^r\hat{\omega}_rω^r 为中心,浓度参数 κ 定义为逆粗糙度 κ=1ρκ = \frac{1}{ρ}κ=ρ1,粗糙度使用一个带 softplus 激活函数的 MLP 输出。
较大的 ρ 值对应于较粗糙的表面和较宽的 vMF 分布
IDE使用这个vMF分布下的一组球面谐波的期望值来编码反射方向的分布
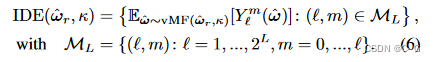
vMF 分布下任何球面谐波的期望值具有以下简单的封闭形式表达式
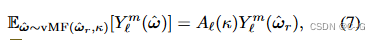
第 lll 个衰减函数 Al(κ)A_l(κ)Al(κ)可以用一个简单的指数函数很好地近似:
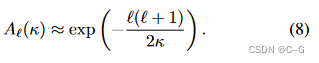
通过降低 κ 来增加材料的粗糙度,对应于用高阶衰减编码的球面谐波,导致更宽的插值核,限制了所代表的视相关颜色中的高频。
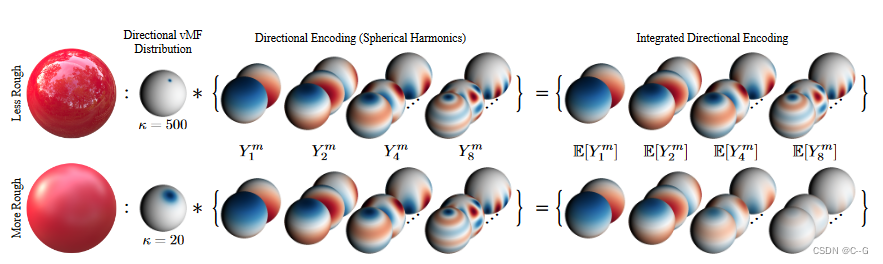
如上图所示,directional MLP可以用集成方向编码来表示任何连续值粗糙度的反射辐射函数,编码的每个分量都是一个与浓度参数 κ 的vMF分布卷积的球谐函数,由空间MLP输出(等效于vMF下的球谐期望)。不太粗糙的位置接收到更高频率的编码(顶部),而更粗糙的区域接收到衰减的高频编码。IDE允许在不同粗糙度的位置之间共享照明信息,并允许编辑反射率
Diffuse and Specular Colors
通过分离漫反射和镜面反射组件,进一步简化 ω^r\hat{\omega}_rω^r 的函数
由于漫反射颜色是(根据定义)唯一位置的函数,修改空间MLP以输出漫反射色 cdc_dcd 和高光色 s,将其与 directional MLP提供的高光色csc_scs 结合起来,以获得一个单一的颜色值
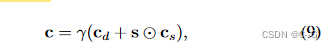
⊙\odot⊙ 表示元素相乘,γ是一个固定的色调映射函数,将线性颜色转换为sRGB,将输出颜色裁剪为位于[0,1]之间
Additional Degrees of Freedom
照明的反射和自遮挡等效果会导致照明在整个场景的空间上发生变化
额外通过空间MLP输出的瓶颈向量 b 进入定向MLP,以便反射辐射可以随着3D位置的变化而变化
Scene Editing
所提出的 ω^r\hat{\omega}_rω^r 结构实现了场景的视图一致编辑。虽然没有将外观进行完全的逆渲染分解为BRDFs和照明,但各个组件的行为直观,并实现了视觉上可信的场景编辑结果,这是标准NeRF无法实现的。

该模型对 ω^r\hat{\omega}_rω^r 的结构将场景外观分解为可解释的组件(顶部行),从而实现编辑(底部行)。注意,在铬材质球(右上角)上的一点的传出辐射度函数是实际场景照明的合理重建。可以在不影响镜面反射的情况下编辑汽车的漫反射颜色,并且可以通过操纵IDE中使用的 κ 值来修改汽车和材质球的粗糙度。
实验
使用略微修改的 Mip-NeRF学习时间表来训练模型、模型的消融和所有Mip-NeRFF基线:250k优化迭代,批次大小为214,使用具有超参数 β1β_1β1 = 0.9, β2β_2β2 = 0.999, ε = 10−6的Adam优化器,学习率从2 × 10−3退火到2 × 10−5,预热阶段为512次迭代,梯度裁剪到范数为10−3。
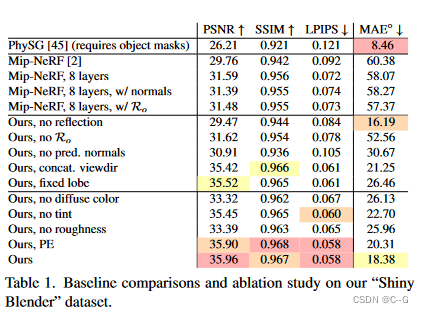
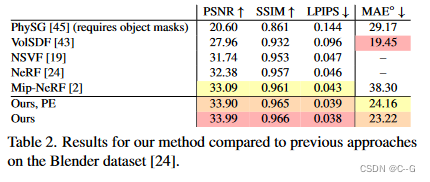

Limitations
虽然nf - nerf显著改善了以前用于视图合成的性能最好的神经场景表示,但它需要增加计算量:评估综合定向编码比计算标准位置编码略慢,通过空间MLP的梯度反向传播来计算法向量使模型比mip-NeRF慢约25%。通过反射方向对出射辐射度的重新参数化,没有明确地模拟相互反射或非远距离照明,因此在这种情况下,对mip-NeRF的改进有所减少。