
Spark源码精读 之 ApplicationMaster
创始人
2024-06-03 22:04:00
1、背景介绍
Spark版本:V2.3.2
2、关键代码
Spark任务提交后,若是集群模式,会将org.apache.spark.deploy.yarn.ApplicationMaster类的main函数作为主入口,并启动进程来运行此类。
def main(args: Array[String]): Unit = {master = new ApplicationMaster(amArgs)System.exit(master.run())
}
我们看下ApplicationMaster函数实例化的时候,有哪些值得关注的信息。
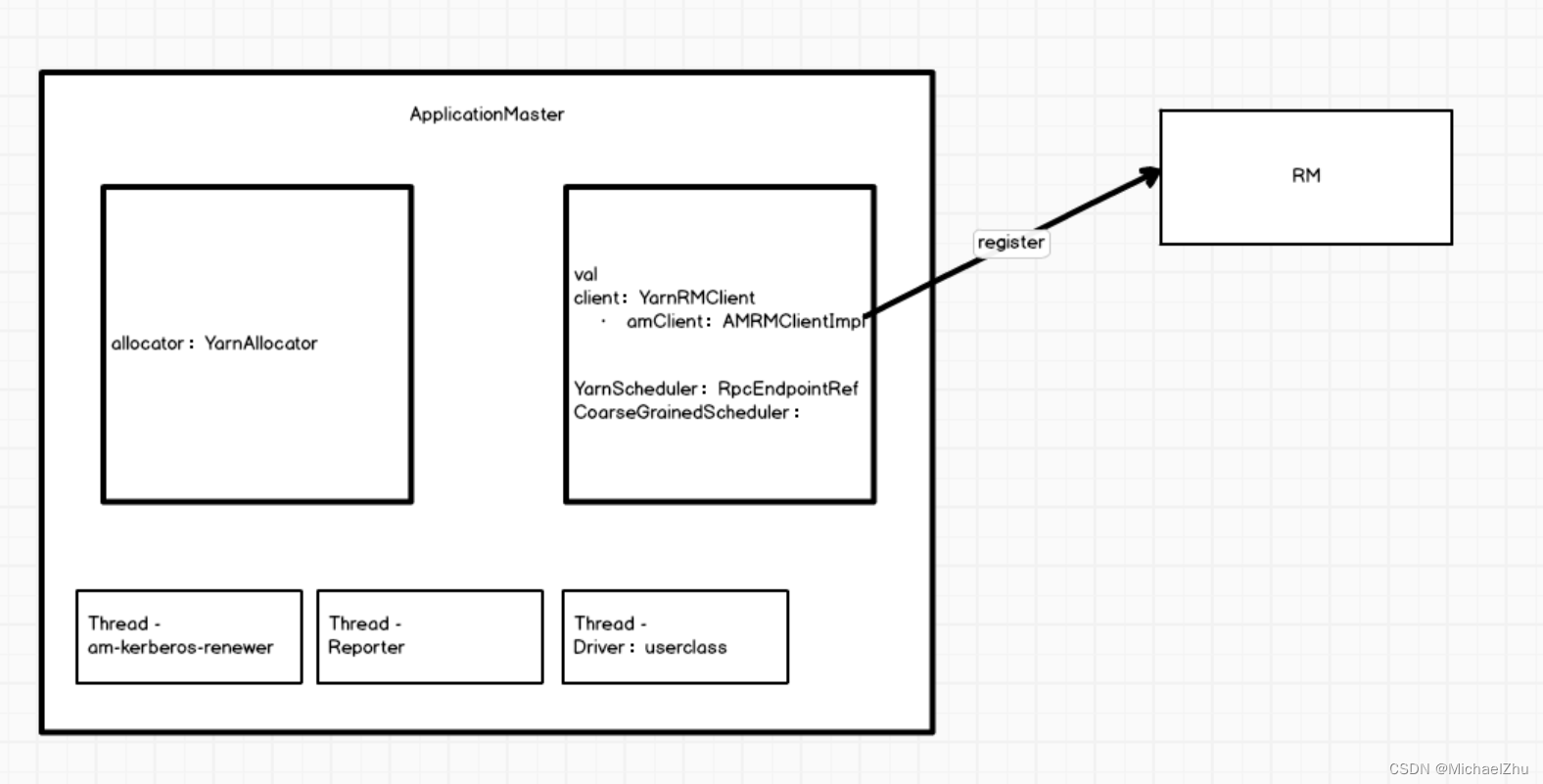
ApplicationMaster
private val client = doAsUser { new YarnRMClient() }YarnRMClient
private var amClient: AMRMClient[ContainerRequest] = _
client就是YarnRMClient函数实例化的对象。
amClient,是AMRMClientImpl函数实例化的对象,后续注册Driver注册AM,就是这个对象去实现的。
接下来是master.run()方法,这里有两条线,一条线是执行–class指向的函数,也就是咱们的Spark代码,另一条线就是向RM注册并分配Containers。
// 第一条线
userClassThread = startUserApplication()// 第二条线
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {val sc = ThreadUtils.awaitResult(sparkContextPromise.future,Duration(totalWaitTime, TimeUnit.MILLISECONDS))if (sc != null) {rpcEnv = sc.env.rpcEnvval driverRef = createSchedulerRef(sc.getConf.get("spark.driver.host"),sc.getConf.get("spark.driver.port"))registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.webUrl))registered = true} userClassThread.join()
在注册AM的同时, 会初始化amClient并由amClient对象完成向RM注册,并返回类型为YarnAllocator的allocator对象。
然后再初始化AM endpoint。
最后由allocator分配资源。
ApplicationMaster
allocator = client.register(driverUrl,driverRef,yarnConf,_sparkConf,uiAddress,historyAddress,securityMgr,localResources)YarnRMClient
amClient = AMRMClient.createAMRMClient()ApplicationMaster
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
allocator.allocateResources()
至此,ApplicationMaster进程资源这一条线完成所有动作,等到另一条线程执行完–class的函数后,完成整个Spark任务。
简单画条流程图,后补详细的。
3、简单流程图
相关内容
热门资讯
在家自己发酵的果酒更天然更健康...
流 “在家自己发酵的果酒更天然更健康?” 经常有网友称“所有水果都能拿来酿酒”“在家自己发酵的果酒更...
浙江茶,中不中?
01春茶季刚过,浙江茶商赴郑州参展,展厅人头攒动,2026“浙江绿茶全国行”郑州茶博会热闹非凡。 0...
来江苏徐州吃什么?当地人推荐这...
#本地看我的# 徐州古称彭城,夏禹分九州时就有它。 五千年前彭祖在此建大彭氏国,活了八百岁,还成了...
原创 豆...
先唠两句原理。鱼和豆腐这对CP,属于典型的“1+1>2”。鱼里有丰富的氨基酸,豆腐里有植物蛋白,两者...