
文本分类模型的训练、调优、蒸馏
什么是文本分类任务?
主题分类
判断邮件是否是垃圾邮件
情感分析
对话系统中的意图识别:如判断聊天用户的意图是“问发货时间”还是问“退换货收货地址
分类模型的发展历史
规则:通过关键词,查词表,按照一定的规则来判断文本属于哪个类别
机器学习:Logistic Regression, SVM, 集成学习
传统深度学习:FastText、TextCNN、BiLSTM
前沿深度学习:Transformer、Bert系列
分类任务的扩展任务
序列标注任务
单字标S, 一个单词的开头表B,结尾标E,中间标M
句子对分类任务
不同于一般的句子分类任务输入的一条句子,这里同时输入的是两个句子
“白日依山尽,黄河入海流” ——> 下一句?“是”
“黄河入海流,白日依山尽”——>是下一句吗?“不是”
BERT的训练过程中经常做个这个任务,也就是NSP Next Sentence Prediction
多标签分类任务
比如一条新闻可能同时涉及 “政治”“经济” “科技”,这一条新闻就被同时打上了3个不同的标签
分类任务的评估指标Metrics
错误率Error rate
分类错误的样本数占总样本数的比例
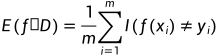
E表示Error rate,f表示模型-分类器,D表示训练样本。E(f;D)表示基于D这个训练样本下,训练出来的分类器的误差
m表示训练样本D中样本的数量。I( )是一个指示函数,括号内的条件成立时,整个函数的值为1,否则为0。f(xi)是是分类器对样本xi的预测分类标签,yi对应样本本xi的真实标签。这里的意思就是如果 预测的标签和真实的标签不相等,就会记作1。
比如10个样本进行预测,预测10次,错了3次。错误率是30%
accuracy
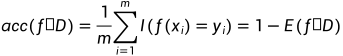
1-Error_rate,就是acc。
比如分类了10次,有9次都是分的和label标签一样,acc就是90%
所有的罪犯里,有多少大比例都被抓到了?——清理坏人,除恶务尽的力度。(尽可能把坏人抓干净)
四个格子加起来(True Positive+True Negative+False Positive+False Negative),一定等于总样本数量
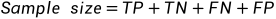
accuracy就是所有分类分对的(T打头的,TP和TN),除以总共的Sample size(就是四个格子加在一起)
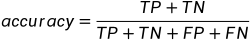
查准率(precision),我判断为阳性的里面,有多少比例真的是阳性呢?
分母:我判断为阳性的(TP TN FP FN 这里四个里面带P,就是我判断为阳性的,一共有两个,也就是TP和FP)。
分子:里面真的是阳性的,且被我判断为阳性的(你去TP TN FP FN这个四个选项里面,挑带T的,只有两个,也就是TP和TN。这两个里面被我判断为阳性的,你找这两个里面带P的,只有一个,也就是TP)
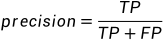
为什么叫precision呢?你判断为阳性positive且真是阳性的,占你总判断为阳性的比例。你判断为阳性这个行为的准确性。
抓到的罪犯里面,有多少真是罪犯?——precision=(1-冤枉好人的概率)。(冤假错案的比例尽可能低,也就是precision尽可能的高)
查全率(recall):所有的阳性中,多大比例被你识别出来了
分母:所有的 真感染
分子:是阳性且被你识别出来的
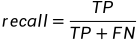
为什么叫recall呢?召回召回,是从你关注的特定领域(所有感染的人)中召回目标类别(真感染了,还能被你判定为阳性)的比例
precision和recall的分子都是TP,precision——所有你判断为阳性里面有多准;recall——所有真感染的人里面,多少能被你召回来住院隔离
precision和recall之间是矛盾的。
为了提高你的precision,使得你判断为阳性的患者确实是真感染的比例提高,你最自然的做法是,尽量少的判定病人感染了。
如果你想提高你的recall,保证所有感染的人中,尽可能多的人能被你判定为阳性,你最简单的做法就是,尽可能多的把来看病的患者判定为阳性。
precision的提高,会让你减少判定为positive的数量;recall的做法,会让你增加判断为positive的数量。所以二者是矛盾的。于是下面出来了一个平衡precision和recall的指标,f1 score,让你可以兼顾这两个内在是矛盾的指标。
f1-score
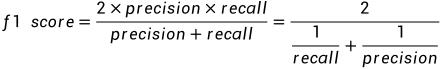
分子是乘法,分母是加法。假设precision和recall都等于1,分子为2×1×1,分母为1+1,分子分母一除等于2/2=1。真好和最完美的分数等于1相吻合。
这个公式其实对precision和recall进行了加权平均(权重各50%)。不信的话,你可以看上面我对F1 score做的恒等变形(分子分母同时除以recall×precision),得到上面第三个式子。
Bagging, Boosting, Random Forest, XGboost