
【hive】order by、sort by、distribute by、cluster by的区别
创始人
2025-05-31 12:38:46
Order By(全局排序)
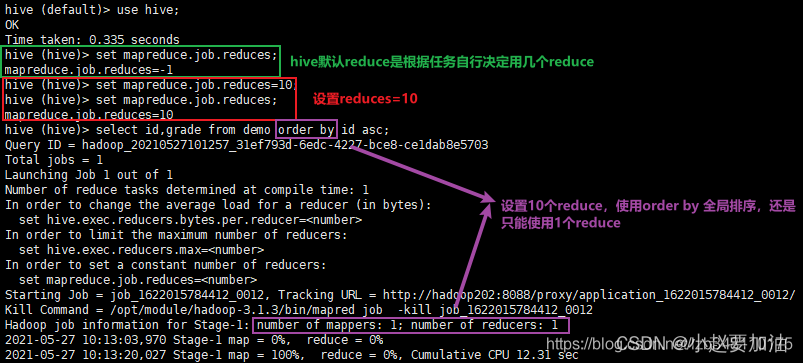
Order By 用于结果集的排序。也可以称之为全局排序。对于 MR 任务来说,如果我们使用了 Order By 排序,意味着MR 任务只会有一个 Reducer 参与排序。,
在 Hive 中执行脚本时,我们可以通过set mapreduce.job.reduces = 10 来设置 reduce 的个数为 10。但只要使用了 Order By 排序,即使设置了 10 个reduce ,也是不会生效的。Order By 就是一个全局排序,只能用一个 Reduce 进行全局排序。
Sort By(每个reduce内部排序)
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。Sort by 在每个 Reducer 内部进行排序,即使每个 reduce 内部是有序的,但是对于全局结果集 来说也还是乱序的。
Distribute By(指定分区规则)
Distribute by 是用来指定Distribute By 是用来指定分区规则的,它结合 Sort By 一起使用。上文介绍的单独使用 Sort By 对部门编号排序,因为没有指定分区规则,Sort By 则随机分区排序。Distribute By 类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。通常是先用 Distribute By 指定分区规则,然后再使用 Sort By 对分区内数据排序。
Cluster By(分区字段和排序字段相同时使用)
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 ASC 或者 DESC。Cluster by 不常用的。
相关内容
热门资讯
实测 2026 贵州包车游!贵...
为什么同样是报贵州定制小团游,有人全程舒心无忧,有人却深陷加价、缩水、推诿的泥潭?结合主流旅游平台投...
原创 海...
今年春节之时,来自海外的游客数量众多,将潮汕小巷挤得满满当当,还纷纷涌入黄山脚下,他们并非是想去观赏...
详释一下张家口酒吧街夜生活指南
# 张家口酒吧街夜生活指南 当夕阳的余晖渐渐隐没在张家口的群山之后,这座城市的另一面开始苏醒。位于市...
宝清县公园哪个最好人气高
宝清县的公园是当地居民休闲娱乐的好去处,每个公园都有其独特的魅力和特色。在众多公园中,究竟哪个公园人...
详谈一下嘉峪关酒吧街夜生活指南
# 嘉峪关酒吧街夜生活指南:戈壁明珠的不眠之夜 在中国西北的戈壁深处,嘉峪关这座古老关城不仅以长城西...