
机器学习框架sklearn之朴素贝叶斯算法
创始人
2025-05-30 06:13:21
概念
朴素:假设特征和特征之间是相互独立的
贝叶斯公式:通常,事件 A 在事件 B 发生的条件下与事件 B 在事件 A 发生的条件下,它们两者的概率并不相同,但是它们两者之间存在一定的相关性,并具有以下公式(称之为“贝叶斯公式”)

朴素贝叶斯算法:朴素+贝叶斯公式
应用场景:文本分类(单词作为特征)
公式
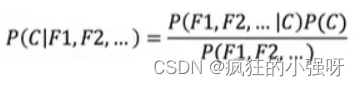
在文章分类中,各部分理解如下:
-
P( C ):每个文档类别的概率(某文档类别数/总文档数量)
-
P(F/C):给定类别下特征(被预测文档中出现的词)的概率
- 计算方法:P(Fi|C)=Ni/N(训练文档中去计算)
- Ni为该Fi词在C类别所有文档中出现的次数
- N为所属类别C下的文档所有词出现的次数和
- P(F1,F2,…)预测文档每个词的概率
- 计算方法:P(Fi|C)=Ni/N(训练文档中去计算)
拉普拉斯平滑系数
目的:防止计算出的分类概率为0
P(Fi|C)=(Ni+a)/(N+a*m)
a为指定的系数一般为1,m为训练文档中统计出的特征词个数
API
sklearn.naive_bayes.MultinomiaINB(alpha=1.0)
-朴素贝叶斯分类
-alpha:拉普拉斯平滑系数
使用演示
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_demo():# 1.获取数据news=fetch_20newsgroups(subset="all")# 2.划分数据集x_train,x_test,y_train,y_test=train_test_split(news.data,news.target)# 3.特征工程:文本特征抽取tf-idftransfer=TfidfVectorizer()x_train=transfer.fit_transform(x_train)x_test=transfer.transform(x_test)# 4.朴素贝叶斯算法预估器流程estimator=MultinomialNB()estimator.fit(x_train,y_train)# 5.模型评估# 方法一y_predict = estimator.predict(x_test)print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法二score = estimator.score(x_test, y_test)print("准确率为:\n", score)# 最佳参数:best_params_print("最佳参数:\n", estimator.best_params_)# 最佳结果:best_score_print("最佳结果:\n", estimator.best_score_)# 最佳估计器:best_estimator_print("最佳估计器:\n", estimator.best_estimator_)# 交叉验证结果:cv_results_print("交叉验证结果:\n", estimator.cv_results_)return None
上一篇:苏桃热门旅游景点推荐及最新资讯
下一篇:迪拜热门景点推荐
相关内容
热门资讯
第十四届龟蒙春节祈福庙会即将启...
齐鲁晚报·齐鲁壹点记者 乔显佳骐骥迎春,登龟蒙接福运,2026年2月17日至2月23日(农历正月初一...
原创 不...
时间过得可真快,一转眼,今天就到腊月廿七了。在我国民间一直流传着一句老话:“腊月二十七,宰鸡赶大集”...
烟火气里迎新春 丰川大地年味浓
腊月岁末,丰川大地年味渐浓,家家户户忙年俗、备年货,蒸花馍、手工压粉条、胡麻油炸油糕成为街头巷尾最动...
每人做道菜温暖老人心!沪郊金山...
春节将至,为了让社区空巢老人感受大家庭的温暖,金山区山阳镇金湾居委会发起了“共享年夜饭”的温情倡议。...