
SparkSQL-SparkOneHive
创始人
2025-05-29 17:53:23
部署
连接Hive操作
小试牛刀:Hive版本的WordCount
从MySQL中读取数据存储到hive中
部署
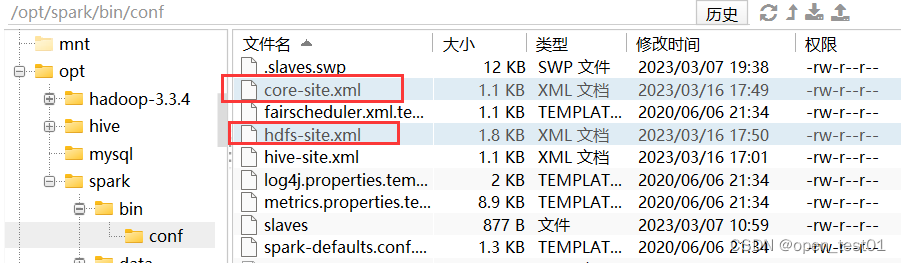
1、Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下

2、把 Mysql 的驱动 copy 到 jars/目录下
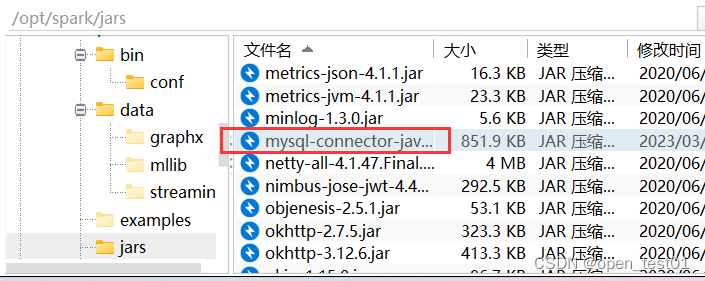
3、 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
导入依赖
org.apache.spark spark-hive_2.12 3.0.0
org.apache.hive hive-exec 1.2.1
mysql mysql-connector-java 5.1.27
将 hive-site.xml 文件拷贝到项目的 resources 目录中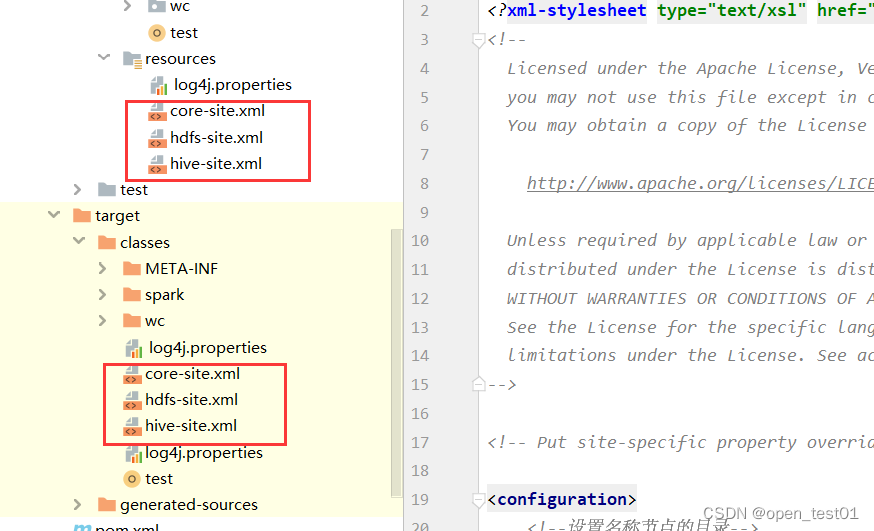
虚拟机中后台启动hive
hiveserver2 &nohup hive --service metastore &连接Hive操作
在操作hive时,需要对哪个库的表进行操作则需要写 -> 数据库名.表名 不然都会默认使用default数据库
spark.sql("select * from ee.user")def main(args: Array[String]): Unit = {//创建Session对象val spark = SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getOrCreate() //创建对象spark.sql("select * from ee.user")spark.close()}小试牛刀:Hive版本的WordCount
注意: 当开启了enableHiveSupport()机制之后可能会导致在本地磁盘的文件会有突然读取不到的清空。原因是hive默认会从HDFS上面获取数据文件
想访问本地磁盘时的解决方法:需在本地磁盘路径前添加file:///
spark.read.text("file:///datas\\a.txt")def main(args: Array[String]): Unit = {//创建Session对象val spark = SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getOrCreate() //创建对象val df: DataFrame = spark.read.text("file:///D:\\spark.test\\datas\\a.txt") //载入数据df.createTempView("wc") //创建表spark.sql("""|select tmp.word,count(tmp.word) from(|select explode(split(value," ")) word from wc|)tmp|group by tmp.word|order by count desc|""".stripMargin).show()spark.close()}从MySQL中读取数据存储到hive中
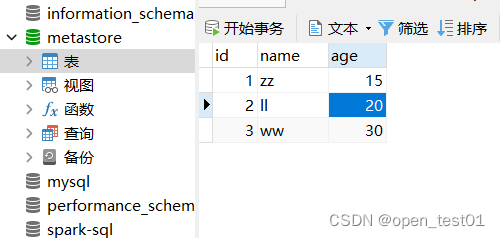
准备MySQL数据库user表
向Hive创建表时 操作hive权限问题 因为是创建到HDFS上所以要提供root用户权限
System.setProperty("HADOOP_USER_NAME","root")def main(args: Array[String]): Unit = {//创建Session对象val spark = SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getOrCreate() //创建对象//从MySQL中读取数据存储到hive中 //添加操作HDFS的用户名System.setProperty("HADOOP_USER_NAME","root")//创建info表spark.sql( //需指定数据库不然会创建到默认数据库下"""|create table ee.test(|id int,|name string,|age int|)|""".stripMargin)//jdbc读取mysqlval pro = new Properties()pro.put("user","root") //指定用户名pro.put("password","p@ssw0rd") //指定密码//jdbc("路径","表名","Properties对象")val df = spark.read.jdbc("jdbc:mysql://master:3306/spark-sql","user",pro)df.write.insertInto("ee.test")spark.sql("select * from ee.test").show()spark.close()}相关内容
热门资讯
官宣!四川又一条国家级户外运动...
2月10日,国家体育总局发布2026年第1号公告——“2026年春节假期户外运动精品线路”,我省“乐...
武汉打车全攻略:出租车好打吗?...
武汉打车全攻略:出租车好打吗?如何避免拒载?本地人教你几招! 很多第一次来武汉的朋友,尤其是带着行李...
护航春节!三亚市市场监管局严查...
为严格落实海南省市场监督管理局春节期间特种设备安全风险提示工作要求,全力保障春节假期全市特种设备安全...
蜜雪冰城墨西哥首店开业,民众排...
当地时间2月12日,蜜雪冰城墨西哥首店在该国首都墨西哥城的宪法广场开业,吸引许多当地民众前往排队购买...
别再冤枉巧克力了!这些健康真相...
🍫 你是否曾因为想吃巧克力而感到内心挣扎?巧克力,这份承载着甜蜜与祝福的礼物,常常被视为“增肥”的代...