
Spark 的JavaWordCount分步详解
一、示例代码
public final class JavaWordCount {private static final Pattern SPACE = Pattern.compile(" ");public static void main(String[] args) throws Exception {if (args.length < 1) { // 保证必须有参数,此参数代表待读取文件System.err.println("Usage: JavaWordCount "); System.exit(1);}SparkSession spark = SparkSession.builder() // 创建SparkSession的构建器.master("local[1]") // 设置部署模式.appName("JavaWordCount") // 设置JavaWordCount例子的应用名称.getOrCreate(); // 使用构建器构造SparkSession实例// 获取DataFrameReader,使用DataFrameReader将文本文件转换为DataFrameJavaRDD lines = spark.read().textFile(args[0]).javaRDD(); // 使用RDD的flatMap 方法对MapPartitionsRDD进行转换JavaRDD words = lines.flatMap(new FlatMapFunction() {@Overridepublic Iterator call(String s) { // 转换函数的作用是对每行文本进行单词拆分return Arrays.asList(SPACE.split(s)).iterator();}});// 使用RDD的mapToPair方法对MapPartitionsRDD进行转换JavaPairRDD ones = words.mapToPair( new PairFunction() {@Override// 转换函数的作用是生成每个单词和1的对偶public Tuple2 call(String s) {return new Tuple2<>(s, 1);}}); // 使用RDD的reduceByKey方法对MapPartitionsRDD进行转换JavaPairRDD counts = ones.reduceByKey(new Function2() {@Override// 转换函数的作用是对每个单词的计数值累加public Integer call(Integer i1, Integer i2) {return i1 + i2;}}); // 使用RDD的collect方法对MapPartitionsRDD及其上游转换进行计算List> output = counts.collect();for (Tuple2 tuple : output) {System.out.println(tuple._1() + ": " + tuple._2());}spark.stop(); // 停止SparkSession
}
}
二、Job准备阶段
在JavaWordCount中,首先对SparkSession和SparkContext进行初始化,然后通过Data-FrameReader的textFile方法生成DataFrame,最后调用RDD的一系列转换API对RDD进行转换并构造出DAG。
1,SparkSession与SparkContext的初始化
JavaWordCount的main方法中首先调用SparkSession的builder方法创建Builder,然后调用Builder的master和appName两个方法给Builder的options中添加spark.master和spark.app.name两个选项,最后调用Builder的getOrCreate方法获取或创建SparkSession实例。在实例化SparkSession的过程中,如果用户没有指定Spark-Context,那么将创建SparkContext并对SparkContext初始化。
2,DataFrame的生成
在创建了SparkSession实例后,调用SparkSession的read方法创建DataFrameReader实例,然后调用DataFrameReader的textFile方法读取参数中指定文件的内容。根据我们对DataFrameReader的textFile方法的分析,我们知道其实际上调用了text方法和select方法,而text方法又依赖于format方法(设置待读取文件的格式)和load方法(读取文件的内容)。DataFrameReader的load方法会将BaseRelation转换为Dataset[Row](即Data-Frame)。
3,RDD的转换与DAG的构建
Dataset刚被实例化的时候,其属性rdd的语句块并未执行,所以当JavaWordCount调用DataSet的javaRDD方法时,会使得rdd的语句块执行。根据我们对rdd语句块的分析,将会调用QueryExecution的toRdd方法。QueryExecution的toRdd方法将使用Spark SQL的执行计划,首先构造FileScanRDD,然后调用RDD的mapPartitionsWithIndex方法创建FileScanRDD的下游MapPartitionsRDD,最后调用RDD的mapPartitionsWithIndexInternal方法创建更下游的MapPartitionsRDD,完成对RDD的部分转换和依赖关系的构建。

由于Spark SQL不属于本书要讲解的内容,所以这里只是简单说明RDD的转换与DAG构建相关的内容。早期版本的Spark中,Spark SQL与RDD的转换及DAG的构建是互相分离的部分,现在的版本已经将部分RDD转换及DAG构建的工作放在了Spark SQL中。
在执行完Spark SQL的执行计划后,还调用RDD的mapPartitions方法构造更下游的MapPartitionsRDD。
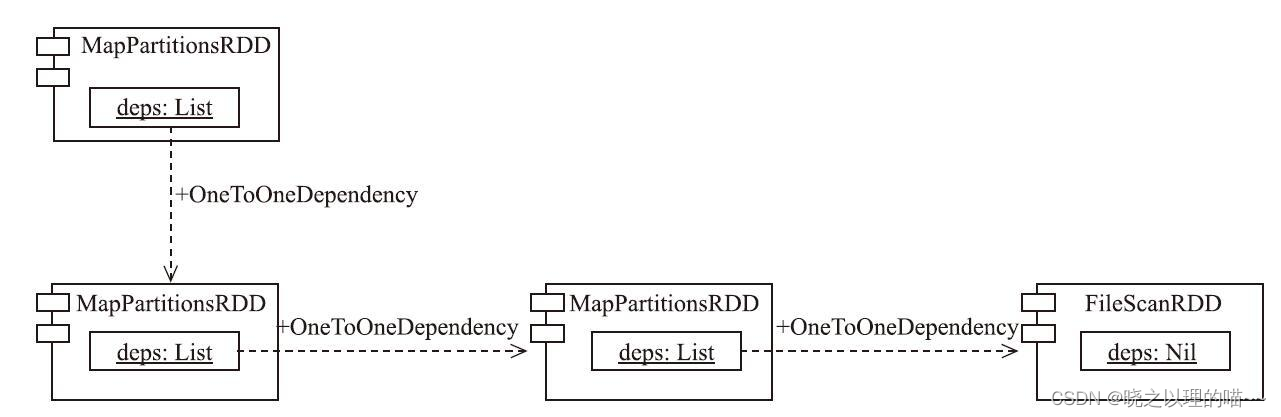
在调用了DataSet的javaRDD方法(实际调用RDD的toJavaRDD方法)后,MapParti-tionsRDD被封装为类型为JavaRDD的lines。
由于JavaRDD继承了特质JavaRDDLike,所以lines的flatMap方法实际是继承自Java-RDDLike的flatMap方法。在调用JavaRDDLike的flatMap方法时,以FlatMapFunction的匿名实现类作为函数参数。
def flatMap[U](f: FlatMapFunction[T, U]): JavaRDD[U] = {def fn: (T) => Iterator[U] = (x: T) => f.call(x).asScalaJavaRDD.fromRDD(rdd.flatMap(fn)(fakeClassTag[U]))(fakeClassTag[U])
}
JavaRDD内部的rdd属性实质是最下游的MapPartitionsRDD,调用Map-Parti-tionsRDD的父类RDD的flatMap方法(见代码清单10-18)构造下游的MapPartitions-RDD。

由于变量words的类型依然是JavaRDD,所以调用words的mapToPair方法其实也继承自特质JavaRDDLike。
def mapToPair[K2, V2](f: PairFunction[T, K2, V2]): JavaPairRDD[K2, V2] = {def cm: ClassTag[(K2, V2)] = implicitly[ClassTag[(K2, V2)]] new JavaPairRDD(rdd.map[(K2, V2)](f)(cm))(fakeClassTag[K2], fakeClassTag[V2])
}
根据mapToPair的实现,在调用JavaRDD内部的rdd(最下游的MapPartitionsRDD)的父类RDD的map方法(见代码清单10-19)时,以PairFunction的匿名实现类作为函数参数,构造下游的MapPartitionsRDD,并将此MapPartitionsRDD封装为JavaPairRDD。
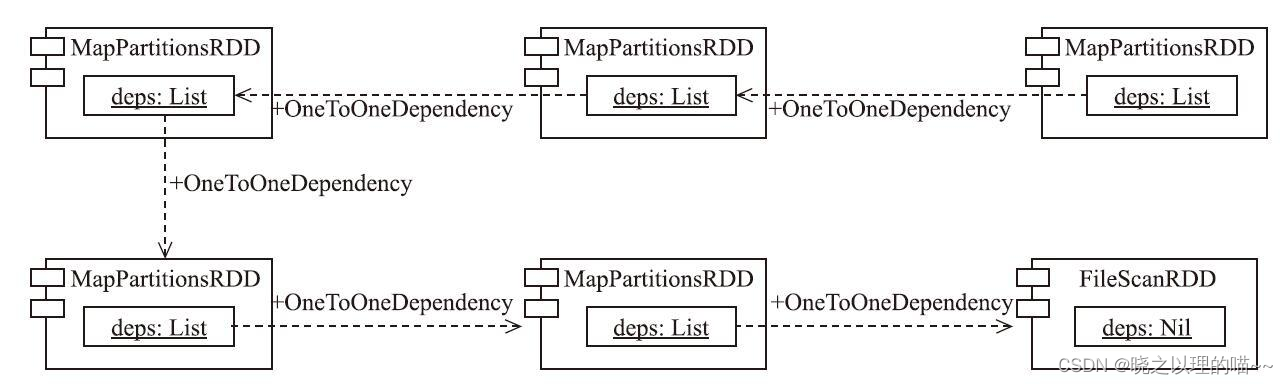
由于变量ones的类型为JavaPairRDD,所以ones的reduceByKey方法继承自JavaPair-RDD。
def reduceByKey(func: JFunction2[V, V, V]): JavaPairRDD[K, V] = {fromRDD(reduceByKey(defaultPartitioner(rdd), func))
}
JavaPairRDD的reduceByKey方法首先调用defaultPartitioner方法获取默认的分区计算器,然后调用JavaPairRDD中重载的另一个reduceByKey方法。
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {val rdds = (Seq(rdd) ++ others)val hasPartitioner = rdds.filter(_.partitioner.exists(_.numPartitions > 0))if (hasPartitioner.nonEmpty) {hasPartitioner.maxBy(_.partitions.length).partitioner.get} else {if (rdd.context.conf.contains("spark.default.parallelism")) {new HashPartitioner(rdd.context.defaultParallelism)} else {new HashPartitioner(rdds.map(_.partitions.length).max)}}
}
defaultPartitioner方法的执行逻辑:
(1)如果RDD中有分区计算器,且分区计算器计算得到的分区数量大于零,那么从这些分区计算器中挑选分区数量最多的那个分区计算器作为当前RDD的分区计算器。
(2)如果RDD中没有分区计算器,则以HashPartitioner作为当前RDD的分区计算器。
JavaPairRDD的reduceByKey方法:
def reduceByKey(partitioner: Partitioner, func: JFunction2[V, V, V]): JavaPair-RDD[K, V] =fromRDD(rdd.reduceByKey(partitioner, func))
PairRDDFunctions的reduceByKey方法:
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
PairRDDFunctions的combineByKeyWithClassTag方法:
def combineByKeyWithClassTag[C](createCombiner: V => C,mergeValue: (C, V) => C,mergeCombiners: (C, C) => C,partitioner: Partitioner,mapSideCombine: Boolean = true,serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0if (keyClass.isArray) {if (mapSideCombine) {throw new SparkException("Cannot use map-side combining with array keys.")}if (partitioner.isInstanceOf[HashPartitioner]) {throw new SparkException("HashPartitioner cannot partition array keys.")}}val aggregator = new Aggregator[K, V, C](self.context.clean(createCombiner),self.context.clean(mergeValue),self.context.clean(mergeCombiners))if (self.partitioner == Some(partitioner)) {self.mapPartitions(iter => {val context = TaskContext.get()new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, con-text))}, preservesPartitioning = true)} else {new ShuffledRDD[K, V, C](self, partitioner).setSerializer(serializer).setAggregator(aggregator).setMapSideCombine(mapSideCombine)}
}
根据combineByKeyWithClassTag方法的实现,其执行步骤:
(1)创建聚合器(Aggregator)。
(2)如果当前RDD的分区计算器与指定的分区计算器相同,则调用RDD的mapParti-tions方法创建MapPartitionsRDD。
(3)如果当前RDD的分区计算器与指定的分区计算器不相同,则创建ShuffledRDD。
在JavaWordCount的例子中,调用combineByKeyWithClassTag方法将创建Shuffled-RDD。需要注意的是,ShuffledRDD的deps为null,这是因为ShuffledRDD的依赖Shuffle-Dependency是在其getDependencies方法被调用时才创建的。
ShuffleDependency的getDependencies方法:
override def getDependencies: Seq[Dependency[_]] = {val serializer = userSpecifiedSerializer.getOrElse {val serializerManager = SparkEnv.get.serializerManagerif (mapSideCombine) {serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[Class-Tag[C]])} else {serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[Class-Tag[V]])}}List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
三、Job的提交与调度
在JavaWordCount的最后,调用了动作API——collect,这将引发对Job的提交和调度。Job的提交与调度大致可以分为Stage的划分、ShuffleMapTask的调度和执行及Result-Task的唤起、调度和执行。

1,Stage的划分
由于counts的类型是JavaPairRDD,所以调用counts的collect方法实际继承自父类AbstractJavaRDDLike。
def collect(): JList[T] =
rdd.collect().toSeq.asJava
代码中主要调用了ShuffledRDD的父类RDD的collect方法。根据collect方法的实现,将由RDD组成的DAG为参数,调用Spark-Context的runJob方法。SparkContext的runJob方法终将调用代码清单4-29中所示的run-Job方法,进而将RDD组成的DAG提交给DAGScheduler进行调度。根据7.5节对DAG-Scheduler的分析,对DAG中的RDD进行阶段划分后的Stage如ShuffleMapTask的调度与执行所示。除了ShuffledRDD被划入ResultStage外,其余的RDD都被划入到了Shuffle-MapStage中。ShuffleMapStage的ID为0,ResultStage的ID为1。
2,ShuffleMapTask的调度与执行
划分完Stage后,虽然首先提交ResultStage,但实际会率先提交ResultStage的父Stage,即ShuffleMapStage。提交ShuffleMapStage时会按照分区数目创建多个ShuffleMapTask,DAGScheduler将这些ShuffleMapTask打包为TaskSet,通过TaskSchedulerImpl的submitTasks方法提交给TaskSchedulerImpl。TaskSchedulerImpl为TaskSet创建TaskSetManager,并将TaskSetManager放入调度池,参与到FIFO或Fair算法中进行调度。在被调度后会向TaskSchedulerImpl申请资源,最后将Task序列化后封装为LaunchTask消息,再发送给CoarseGrainedExecutorBackend。CoarseGrainedExecutorBackend接收到LaunchTask消息后将调用Executor的launchTask方法。Executor的launchTask方法在运行Task时将创建TaskRunner,TaskRunner实现了Runnable接口的run方法。TaskRunner的run方法中将调用Task的run方法,Task的run方法将调用具体Task实现类(此时为ShuffleMapTask)的runTask方法。ShuffleMapTask经过迭代计算后,将结果通过SortShuffleWriter写入磁盘。
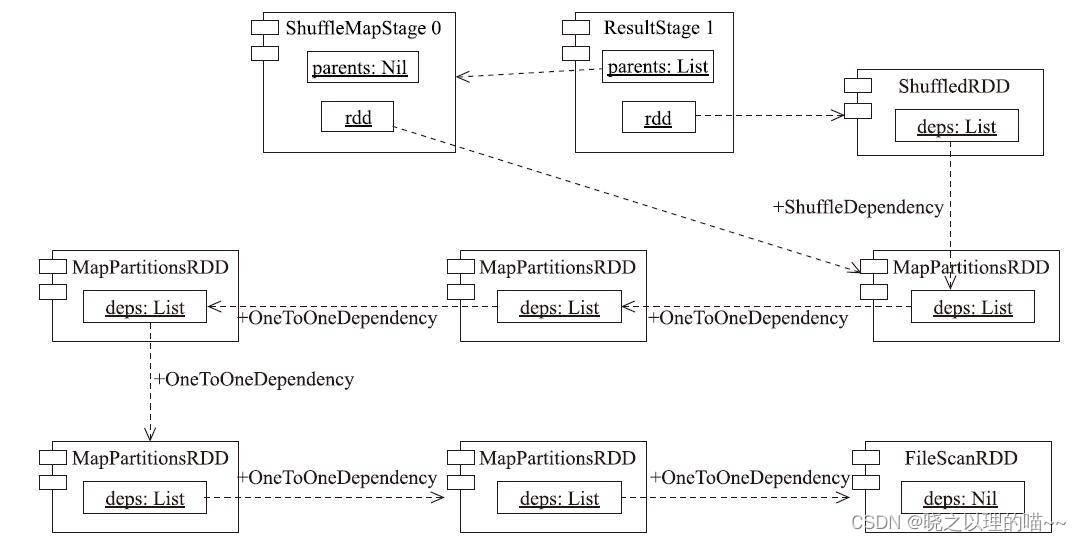
ShuffleMapTask经过RDD管道中对iterator和computeOrReadCheckpoint的层层调用,最终到达FileScanRDD。查看此时的线程栈会更直观,如图10-15所示。看到最底层执行计算的RDD是FileScanRDD,其compute方法实际是读取文件列表中每个文件的内容,对其compute方法的实现感兴趣的读者可自行查阅。根据对MapPartitionsRDD的compute方法的分析,ShuffleMapTask将在迭代计算的过程中完成对从文件中读取的每行数据的分词、计数和聚合。
3,ResultTask的唤起、调度与执行
TaskRunner将在ShuffleMapTask执行成功后调用SchedulerBackend的实现类(比如local模式下的LocalSchedulerBackend或Standalone模式下的StandaloneSchedulerBackend)的statusUpdate方法,最终导致TaskSchedulerImpl的statusUpdate方法被调用。TaskScheduler-Impl的statusUpdate方法(可回顾7.8.2节的分析)发现Task是执行成功的状态,那么调用TaskResultGetter的enqueueSuccessfulTask方法获取ShuffleMapTask的状态,并将此状态交给DAGScheduler处理。DAGScheduler的taskEnded方法对于ShuffleMapTask,需要将Stage的shuffleId和outputLocs中的MapStatus注册到mapOutputTracker。如果有某些分区的Task执行失败,则重新提交ShuffleMapStage,否则调用submitWaitingChildStages方法提交当前ShuffleMapStage的子Stage(即ResultStage)。ResultStage的提交与调度同ShuffleMapStage大致相同,区别有:会按照分区数量创建多个ResultTask;Task的run方法将调用ResultTask的runTask方法;ResultTask经过迭代计算后不会将结果写入磁盘。
根据我们对ShuffledRDD的compute方法的分析,ShuffledRDD将使用BlockStoreShuffleReader的read方法获取ShuffleMapTask输出的Block并在reduce端进行聚合或排序。ResultTask执行成功的结果最后也交由DAG-Scheduler的taskEnded方法处理,taskEnded方法中会调用JobWaiter的resultHandler函数将各个ResultTask的结果收拢。最后通过JavaWordCount例子中的打印语句将整个Job的执行结果打印出来。
文章来源:《Spark内核设计的艺术:架构设计与实现》 作者:耿嘉安
文章内容仅供学习交流,如有侵犯,联系删除哦!