
李宏毅机器学习作业 HW01 数据集解析和代码分享
创始人
2024-06-03 17:05:17
ML2023Spring - HW01 相关信息:
课程主页
课程视频
Kaggle link
Sample code
HW01 视频 可以在做作业之前看一部分,我摸索完才发现视频有讲 Data Feature 😦
HW01 PDF
个人完整代码分享
P.S. 即便 kaggle 上的时间已经截止,你仍然可以在上面提交和查看分数。但需要注意的是:在 kaggle 截止日期前你应该选择两个结果进行最后的Private评分。
每年的数据集size和feature并不完全相同,但基本一致,过去的代码仍可用于新一年的 Homework
文章目录
- 任务目标(回归)
- 性能指标(Metric)
- 数据解析
- Sample code 主体部分解析
- Some Utility Functions
- Dataset
- Neural Network Model
- Feature Selection
- Training Loop
- Configurations
任务目标(回归)
- COVID-19 daily cases prediction: COVID-19 每天的病例预测
- 训练/测试数据大小:3009/997(每一年的homework 可能不同)
性能指标(Metric)
- 均方误差 Mean Squared Error (MSE)
数据解析
- covid_train.txt: 训练数据
- covid_test.txt: 测试数据
数据大体分为三个部分:id, states: 病例对应的地区, 以及其他数据
- id: sample 对应的序号。
- states: 对 sample 来说该项为 one-hot vector。从整个数据集上来看,每个地区的 sample 数量是均匀的,可以使用
pd.read_csv('./covid_train.csv').iloc[:,1:34].sum()来查看,地区 sample 数量为 88/89。 - 其他数据: 这一部分最终应用在助教所给的 sample code 中的 select_feat。
- Covid-like illness (5) 新冠症状
- cli, ili …
- Behavier indicators (5) 行为表现
- wearing_mask、travel_outside_state … 是否戴口罩,出去旅游 …
- Belief indicators (2) 是否相信某种行为对防疫有效
- belief_mask_effective, belief_distancing_effective. 相信戴口罩有效,相信保持距离有效。
- Mental indicator (2) 心理表现
- worried_catch_covid, worried_finance. 担心得到covid,担心经济状况
- Environmental indicators (3) 环境表现
- other_masked_public, other_distanced_public … 周围的人是否大部分戴口罩,周围的人是否大部分保持距离 …
- Tested Positive Cases (1) 检测阳性病例,该项为模型的预测目标
- tested_positive (this is what we want to predict) 单位为百分比,指有多少比例的人
- Covid-like illness (5) 新冠症状
Sample code 主体部分解析
Some Utility Functions
def same_seed(seed): '''Fixes random number generator seeds for reproducibility.'''# 使用确定的卷积算法 (A bool that, if True, causes cuDNN to only use deterministic convolution algorithms.)torch.backends.cudnn.deterministic = True # 不对多个卷积算法进行基准测试和选择最优 (A bool that, if True, causes cuDNN to benchmark multiple convolution algorithms and select the fastest.)torch.backends.cudnn.benchmark = False # 设置随机数种子np.random.seed(seed)torch.manual_seed(seed)if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)def train_valid_split(data_set, valid_ratio, seed):'''Split provided training data into training set and validation set'''valid_set_size = int(valid_ratio * len(data_set)) train_set_size = len(data_set) - valid_set_sizetrain_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))return np.array(train_set), np.array(valid_set)def predict(test_loader, model, device):# 用于评估模型(验证/测试)model.eval() # Set your model to evaluation mode.preds = []for x in tqdm(test_loader):# device (int, optional): if specified, all parameters will be copied to that device) x = x.to(device) # 将数据 copy 到 devicewith torch.no_grad(): # 禁用梯度计算,以减少消耗 pred = model(x) preds.append(pred.detach().cpu()) # detach() 创建一个不在计算图中的新张量,值相同preds = torch.cat(preds, dim=0).numpy() # 连接 preds return preds
Dataset
class COVID19Dataset(Dataset):'''x: Features.y: Targets, if none, do prediction.'''def __init__(self, x, y=None):if y is None:self.y = yelse:self.y = torch.FloatTensor(y)self.x = torch.FloatTensor(x)'''meth:`__getitem__`, supporting fetching a data sample for a given key.'''def __getitem__(self, idx): # 自定义 dataset 的 idx 对应的 sampleif self.y is None:return self.x[idx]else:return self.x[idx], self.y[idx]def __len__(self):return len(self.x)
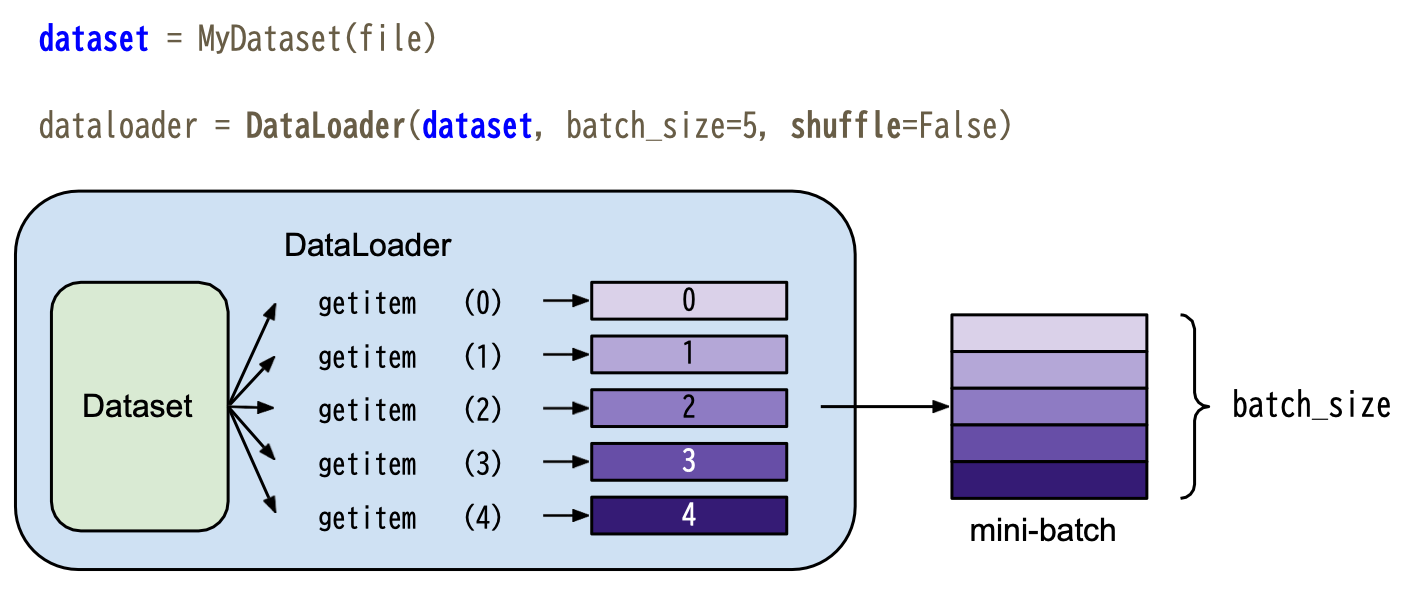
__getitem__()实际应用于 dataloader 中,详细可见下图(图源自 PyTorch Tutorial PDF)
Neural Network Model
这部分我做了简单的修改,以便于后续调参
class My_Model(nn.Module):def __init__(self, input_dim):super(My_Model, self).__init__()# TODO: modify model's structure in hyper-parameter: 'config', be aware of dimensions.self.layers = nn.Sequential(nn.Linear(input_dim, config['layer'][0]),nn.ReLU(),nn.Linear(config['layer'][0], config['layer'][1]),nn.ReLU(),nn.Linear(config['layer'][1], 1))def forward(self, x):x = self.layers(x)x = x.squeeze(1) # (B, 1) -> (B)return x
Feature Selection
这部分可以使用 sklearn.feature_selection.SelectKBest 来进行特征选择。
具体代码如下(你可能需要传入 config):
from sklearn.feature_selection import SelectKBest, f_regressionk = config['k'] # 所要选择的特征数量
selector = SelectKBest(score_func=f_regression, k=k)
result = selector.fit(train_data[:, :-1], train_data[:,-1])
idx = np.argsort(result.scores_)[::-1]
feat_idx = list(np.sort(idx[:k]))
Training Loop
def trainer(train_loader, valid_loader, model, config, device):criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.# Define your optimization algorithm. # TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=config['momentum']) # 设置 optimizer 为SGDwriter = SummaryWriter() # Writer of tensoboard.if not os.path.isdir('./models'):os.mkdir('./models') # Create directory of saving models.n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0for epoch in range(n_epochs):model.train() # Set your model to train mode.loss_record = [] # 初始化空列表,用于记录训练误差# tqdm is a package to visualize your training progress.train_pbar = tqdm(train_loader, position=0, leave=True) # 让训练进度显示出来,可以去除这一行,然后将下面的 train_pbar 改成 train_loader(目的是尽量减少 jupyter notebook 的打印,因为如果这段代码在 kaggle 执行,在一定的输出后会报错: IOPub message rate exceeded...)for x, y in train_pbar:optimizer.zero_grad() # Set gradient to zero.x, y = x.to(device), y.to(device) # Move your data to device. pred = model(x) # 等价于 model.forward(x) loss = criterion(pred, y) # 计算 pred 和 y 的均方误差loss.backward() # Compute gradient(backpropagation).optimizer.step() # Update parameters.step += 1loss_record.append(loss.detach().item())# Display current epoch number and loss on tqdm progress bar.train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')train_pbar.set_postfix({'loss': loss.detach().item()})mean_train_loss = sum(loss_record)/len(loss_record)writer.add_scalar('Loss/train', mean_train_loss, step)model.eval() # Set your model to evaluation mode.loss_record = [] # 初始化空列表,用于记录验证误差for x, y in valid_loader:x, y = x.to(device), y.to(device)with torch.no_grad():pred = model(x)loss = criterion(pred, y)loss_record.append(loss.item())mean_valid_loss = sum(loss_record)/len(loss_record)print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')# writer.add_scalar('Loss/valid', mean_valid_loss, step)if mean_valid_loss < best_loss:best_loss = mean_valid_losstorch.save(model.state_dict(), config['save_path']) # Save your best modelprint('Saving model with loss {:.3f}...'.format(best_loss))early_stop_count = 0else: early_stop_count += 1if early_stop_count >= config['early_stop']:print('\nModel is not improving, so we halt the training session.')return
Configurations
我修改了 sample code 中 config 里面的一些参数,用于达成 boss-baseline,如果你还没有进行自己的思考,先不要看这段,因为这其中包含了一些我的调参想法。
个人完整代码分享
device = 'cuda' if torch.cuda.is_available() else 'cpu' # If you use Apple chip, you could change 'cpu' to 'mps'config = {'seed': 5201314, # Your seed number, you can pick your lucky number. :)'k': 16, # Select k feature'layer': [16, 16], # Modify you model's structure 'momentum': 0.7,'valid_ratio': 0.2, # validation_size = train_size * valid_ratio'n_epochs': 10000, # Number of epochs.'batch_size': 256,'learning_rate': 1e-5,'weight_decay': 1e-5,'early_stop': 600, # If model has not improved for this many consecutive epochs, stop training.'save_path': './models/model.ckpt', # Your model will be saved here.'select_all': True, # Whether to use all features. 'no_momentum': False, # Whether to use momentum'no_normal': True, # Whether to normalize data'no_k_cross': False, # Whether to use K-fold cross validation
}
参考链接:
- PyTorch: What is the difference between tensor.cuda() and tensor.to(torch.device(“cuda:0”))?
- PyTorch Tutorial PDF
相关内容
热门资讯
一场“杀糕局”,如何成为05后...
来源:吴晓波频道CHANNELWU “今天成为蛋糕‘杀手’。” 社交平台上,年轻人们流行起一种名为“...
原创 糯...
说实话,以前我一直觉得糯米蒸排骨是个技术活,光听名字就觉得高大上,肯定得是大厨才能搞定。直到有一次去...
一碗汤和一块肉,谁更营养?真相...
中国人餐桌上,永远少不了一碗汤。 生病了?喝碗鸡汤补补。 手术后?炖锅鱼汤养养。 坐月子?猪脚汤、鲫...
【佑安•二十四节气明信片】健康...
编者语 春生夏长,秋收冬藏,二十四节气藏着中国人的养生智慧。北京佑安医院立足专科特色,以节气为序,凝...